6.7. Introductory Overview of PyMC#
Note: This text is partly based on the PeerJ CS publication on PyMC by John Salvatier, Thomas V. Wiecki, and Christopher Fonnesbeck.
Abstract#
Probabilistic Programming allows for automatic Bayesian inference on user-defined probabilistic models. Gradient-based algorithms for Markov chain Monte Carlo (MCMC) sampling, known as Hamiltonian Monte Carlo (HMC), allow inference on increasingly complex models but requires gradient information that is often not trivial to calculate. PyMC is an open source probabilistic programming framework written in Python that uses PyTensor to compute gradients via automatic differentiation, as well as compiling probabilistic programs on-the-fly to one of a suite of computational backends for increased speed. PyMC allows for model specification in Python code, rather than in a domain-specific language, making it easy to learn, customize, and debug. This paper is a tutorial-style introduction to this software package for those already somewhat familiar with Bayesian statistics.
Introduction#
Probabilistic programming (PP) allows flexible specification of Bayesian statistical models in code. PyMC is a PP framework with an intuitive and readable, yet powerful, syntax that is close to the natural syntax statisticians use to describe models. It features next-generation Markov chain Monte Carlo (MCMC) sampling algorithms such as the No-U-Turn Sampler (NUTS; Hoffman, 2014), a self-tuning variant of Hamiltonian Monte Carlo (HMC; Duane, 1987). This class of samplers works well on high-dimensional and complex posterior distributions and allows many complex models to be fit without specialized knowledge about fitting algorithms. HMC and NUTS take advantage of gradient information from the likelihood to achieve much faster convergence than traditional sampling methods, especially for larger models. NUTS also has several self-tuning strategies for adaptively setting the tunable parameters of Hamiltonian Monte Carlo, which means you usually don’t need to have specialized knowledge about how the algorithms work.
Probabilistic programming in Python confers a number of advantages including multi-platform compatibility, an expressive yet clean and readable syntax, easy integration with other scientific libraries, and extensibility via C, C++, Fortran or Cython. These features make it relatively straightforward to write and use custom statistical distributions, samplers and transformation functions, as required by Bayesian analysis.
While most of PyMC’s user-facing features are written in pure Python, it leverages PyTensor (a fork of the Theano project) to transparently transcode models to C and compile them to machine code, thereby boosting performance. PyTensor is a library that allows expressions to be defined using generalized vector data structures called tensors, which are tightly integrated with the popular NumPy ndarray data structure, and similarly allow for broadcasting and advanced indexing, just as NumPy arrays do. PyTensor also automatically optimizes the likelihood’s computational graph for speed and allows for compilation to a suite of computational backends, including Jax and Numba.
Here, we present a primer on the use of PyMC for solving general Bayesian statistical inference and prediction problems. We will first see the basics of how to use PyMC, motivated by a simple example: installation, data creation, model definition, model fitting and posterior analysis. Then we will cover two case studies and use them to show how to define and fit more sophisticated models. Finally we will discuss a couple of other useful features: custom distributions and arbitrary deterministic nodes.
License#
PyMC is distributed under the liberal Apache License 2.0. On the GitHub site, users may also report bugs and other issues, as well as contribute documentation or code to the project, which we actively encourage.
A Motivating Example: Linear Regression#
To introduce model definition, fitting, and posterior analysis, we first consider a simple Bayesian linear regression model with normally-distributed priors for the parameters. We are interested in predicting outcomes \(Y\) as normally-distributed observations with an expected value \(\mu\) that is a linear function of two predictor variables, \(X_1\) and \(X_2\):
where \(\alpha\) is the intercept, and \(\beta_i\) is the coefficient for covariate \(X_i\), while \(\sigma\) represents the observation error. Since we are constructing a Bayesian model, we must assign a prior distribution to the unknown variables in the model. We choose zero-mean normal priors with variance of 100 for both regression coefficients, which corresponds to weak information regarding the true parameter values. We choose a half-normal distribution (normal distribution bounded at zero) as the prior for \(\sigma\).
Generating data#
We can simulate some artificial data from this model using only NumPy’s random module, and then use PyMC to try to recover the corresponding parameters. We are intentionally generating the data to closely correspond the PyMC model structure.
import arviz as az
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
%config InlineBackend.figure_format = 'retina'
# Initialize random number generator
RANDOM_SEED = 8927
rng = np.random.default_rng(RANDOM_SEED)
az.style.use("arviz-darkgrid")
# True parameter values
alpha, sigma = 1, 1
beta = [1, 2.5]
# Size of dataset
size = 100
# Predictor variable
X1 = np.random.randn(size)
X2 = np.random.randn(size) * 0.2
# Simulate outcome variable
Y = alpha + beta[0] * X1 + beta[1] * X2 + rng.normal(size=size) * sigma
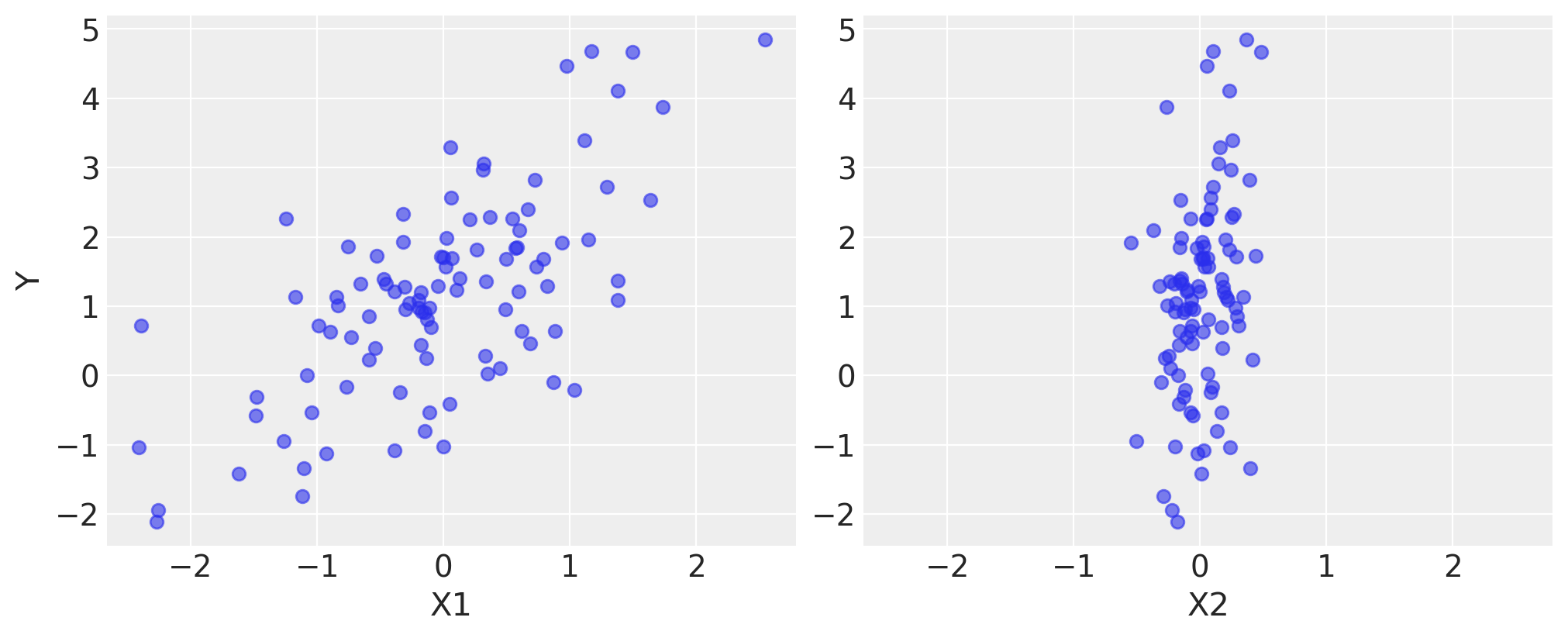
Here is what the simulated data look like. We use the pylab module from the plotting library matplotlib.
fig, axes = plt.subplots(1, 2, sharex=True, figsize=(10, 4))
axes[0].scatter(X1, Y, alpha=0.6)
axes[1].scatter(X2, Y, alpha=0.6)
axes[0].set_ylabel("Y")
axes[0].set_xlabel("X1")
axes[1].set_xlabel("X2");
Model Specification#
Specifying this model in PyMC is straightforward because the syntax is similar to the statistical notation. For the most part, each line of Python code corresponds to a line in the model notation above.
First, we import PyMC. We use the convention of importing it as pm.
import pymc as pm
print(f"Running on PyMC v{pm.__version__}")
Running on PyMC v5.10.4
Now we build our model, which we will present in full first, then explain each part line-by-line.
basic_model = pm.Model()
with basic_model:
# Priors for unknown model parameters
alpha = pm.Normal("alpha", mu=0, sigma=10)
beta = pm.Normal("beta", mu=0, sigma=10, shape=2)
sigma = pm.HalfNormal("sigma", sigma=1)
# Expected value of outcome
mu = alpha + beta[0] * X1 + beta[1] * X2
# Likelihood (sampling distribution) of observations
Y_obs = pm.Normal("Y_obs", mu=mu, sigma=sigma, observed=Y)
The first line,
basic_model = pm.Model()
creates a new Model object which is a container for the model random variables.
Following instantiation of the model, the subsequent specification of the model components is performed inside a with statement:
with basic_model:
This creates a context manager, with our basic_model as the context, that includes all statements until the indented block ends. This means all PyMC objects introduced in the indented code block below the with statement are added to the model behind the scenes. Absent this context manager idiom, we would be forced to manually associate each of the variables with basic_model right after we create them. If you try to create a new random variable without a with model: statement, it will raise an error since there is no obvious model for the variable to be added to.
The first three statements in the context manager:
alpha = pm.Normal('alpha', mu=0, sigma=10)
beta = pm.Normal('beta', mu=0, sigma=10, shape=2)
sigma = pm.HalfNormal('sigma', sigma=1)
create stochastic random variables with normally-distributed prior distributions for the regression coefficients with a mean of 0 and standard deviation of 10, and a half-normal distribution for the standard deviation of the observations, \(\sigma\). These are stochastic because their values are partly determined by their parents in the dependency graph of random variables, which for priors are simple constants, and partly random (or stochastic).
We call the pm.Normal constructor to create a random variable to use as a normal prior. The first argument is always the name of the random variable, which should almost always match the name of the Python variable being assigned to, since it is sometimes used to retrieve the variable from the model for summarizing output. The remaining required arguments for a stochastic object are the parameters, in this case mu, the mean, and sigma, the standard deviation, which we assign hyperparameter values for the model. In general, a distribution’s parameters are values that determine the location, shape or scale of the random variable, depending on the parameterization of the distribution. Most commonly-used distributions, such as Beta, Exponential, Categorical, Gamma, Binomial and many others, are available in PyMC.
The beta variable has an additional shape argument to denote it as a vector-valued parameter of size 2. The shape argument is available for all distributions and specifies the length or shape of the random variable, but is optional for scalar variables, since it defaults to a value of one. It can be an integer to specify an array, or a tuple to specify a multidimensional array (e.g. shape=(5,7) makes a random variable that takes on 5 by 7 matrix values).
Detailed notes about distributions, sampling methods and other PyMC functions are available in the API documentation.
Having defined the priors, the next statement creates the expected value mu of the outcomes, specifying the linear relationship:
mu = alpha + beta[0]*X1 + beta[1]*X2
This creates a deterministic random variable, which implies that its value is completely determined by its parents’ values. That is, there is no uncertainty beyond that which is inherent in the parents’ values. Here, mu is just the sum of the intercept alpha and the two products of the coefficients in beta and the predictor variables, whatever their values may be.
PyMC random variables and data can be arbitrarily added, subtracted, divided, multiplied together and indexed-into to create new random variables. This allows for great model expressivity. Many common mathematical functions like sum, sin, exp and linear algebra functions like dot (for inner product) and inv (for inverse) are also provided.
The final line of the model defines Y_obs, the sampling distribution of the outcomes in the dataset.
Y_obs = Normal('Y_obs', mu=mu, sigma=sigma, observed=Y)
This is a special case of a stochastic variable that we call an observed stochastic, and represents the data likelihood of the model. It is identical to a standard stochastic, except that its observed argument, which passes the data to the variable, indicates that the values for this variable were observed, and should not be changed by any fitting algorithm applied to the model. The data can be passed in the form of either a ndarray or DataFrame object.
Notice that, unlike for the priors of the model, the parameters for the normal distribution of Y_obs are not fixed values, but rather are the deterministic object mu and the stochastic sigma. This creates parent-child relationships between the likelihood and these two variables.
with basic_model:
# draw 1000 posterior samples
idata = pm.sample()
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [alpha, beta, sigma]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 25 seconds.
The sample function runs the step method(s) assigned (or passed) to it for the given number of iterations and returns an InferenceData object containing the samples collected, along with other useful attributes like statistics of the sampling run and a copy of the observed data. Notice that sample generated a set of parallel chains, depending on how many compute cores are on your machine.
idata
-
<xarray.Dataset> Size: 136kB Dimensions: (chain: 4, draw: 1000, beta_dim_0: 2) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 4 5 6 7 ... 993 994 995 996 997 998 999 * beta_dim_0 (beta_dim_0) int64 16B 0 1 Data variables: alpha (chain, draw) float64 32kB 1.224 1.186 1.104 ... 1.151 1.088 beta (chain, draw, beta_dim_0) float64 64kB 0.9859 1.315 ... 1.88 sigma (chain, draw) float64 32kB 1.189 0.8304 1.048 ... 0.972 0.868 Attributes: created_at: 2024-03-09T23:51:24.578206 arviz_version: 0.17.0 inference_library: pymc inference_library_version: 5.10.4 sampling_time: 25.277377128601074 tuning_steps: 1000 -
<xarray.Dataset> Size: 496kB Dimensions: (chain: 4, draw: 1000) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 4 5 ... 995 996 997 998 999 Data variables: (12/17) diverging (chain, draw) bool 4kB False False ... False False perf_counter_diff (chain, draw) float64 32kB 0.0005148 ... 0.0004831 smallest_eigval (chain, draw) float64 32kB nan nan nan ... nan nan lp (chain, draw) float64 32kB -154.8 -154.1 ... -152.9 index_in_trajectory (chain, draw) int64 32kB 2 2 -1 -1 -1 ... 3 2 1 -2 1 n_steps (chain, draw) float64 32kB 3.0 3.0 3.0 ... 7.0 3.0 ... ... process_time_diff (chain, draw) float64 32kB 0.000516 ... 0.000484 step_size_bar (chain, draw) float64 32kB 0.9609 0.9609 ... 0.9344 energy_error (chain, draw) float64 32kB 0.2729 -0.1625 ... 0.4465 largest_eigval (chain, draw) float64 32kB nan nan nan ... nan nan perf_counter_start (chain, draw) float64 32kB 9.957e+04 ... 9.957e+04 max_energy_error (chain, draw) float64 32kB 0.2729 -0.5636 ... 0.4465 Attributes: created_at: 2024-03-09T23:51:24.594557 arviz_version: 0.17.0 inference_library: pymc inference_library_version: 5.10.4 sampling_time: 25.277377128601074 tuning_steps: 1000 -
<xarray.Dataset> Size: 2kB Dimensions: (Y_obs_dim_0: 100) Coordinates: * Y_obs_dim_0 (Y_obs_dim_0) int64 800B 0 1 2 3 4 5 6 ... 93 94 95 96 97 98 99 Data variables: Y_obs (Y_obs_dim_0) float64 800B -1.038 1.982 ... 0.9819 0.6345 Attributes: created_at: 2024-03-09T23:51:24.599350 arviz_version: 0.17.0 inference_library: pymc inference_library_version: 5.10.4
The various attributes of the InferenceData object can be queried in a similar way to a dict containing a map from variable names to numpy.arrays. For example, we can retrieve the sampling trace from the alpha latent variable by using the variable name as an index to the idata.posterior attribute. The first dimension of the returned array is the chain index, the second dimension is the sampling index, while the later dimensions match the shape of the variable. We can see the first 5 values for the alpha variable in each chain as follows:
idata.posterior["alpha"].sel(draw=slice(0, 4))
<xarray.DataArray 'alpha' (chain: 4, draw: 5)> Size: 160B
array([[1.22370772, 1.1856579 , 1.10356325, 1.00517795, 0.97804394],
[1.07550534, 1.27741762, 1.0231154 , 1.1731767 , 1.22227655],
[1.36927792, 0.98713105, 1.32817166, 1.00082131, 1.30191511],
[1.18241155, 1.11625651, 1.25138462, 1.1062831 , 1.20611782]])
Coordinates:
* chain (chain) int64 32B 0 1 2 3
* draw (draw) int64 40B 0 1 2 3 4If we wanted to use the slice sampling algorithm to sample our parameters instead of NUTS (which was assigned automatically), we could have specified this as the step argument for sample.
with basic_model:
# instantiate sampler
step = pm.Slice()
# draw 5000 posterior samples
slice_idata = pm.sample(5000, step=step)
Multiprocess sampling (4 chains in 4 jobs)
CompoundStep
>Slice: [alpha]
>Slice: [beta]
>Slice: [sigma]
Sampling 4 chains for 1_000 tune and 5_000 draw iterations (4_000 + 20_000 draws total) took 27 seconds.
Posterior analysis#
PyMC’s plotting and diagnostics functionalities are now taken care of by a dedicated, platform-agnostic package named Arviz. A simple posterior plot can be created using plot_trace.
az.plot_trace(idata, combined=True);
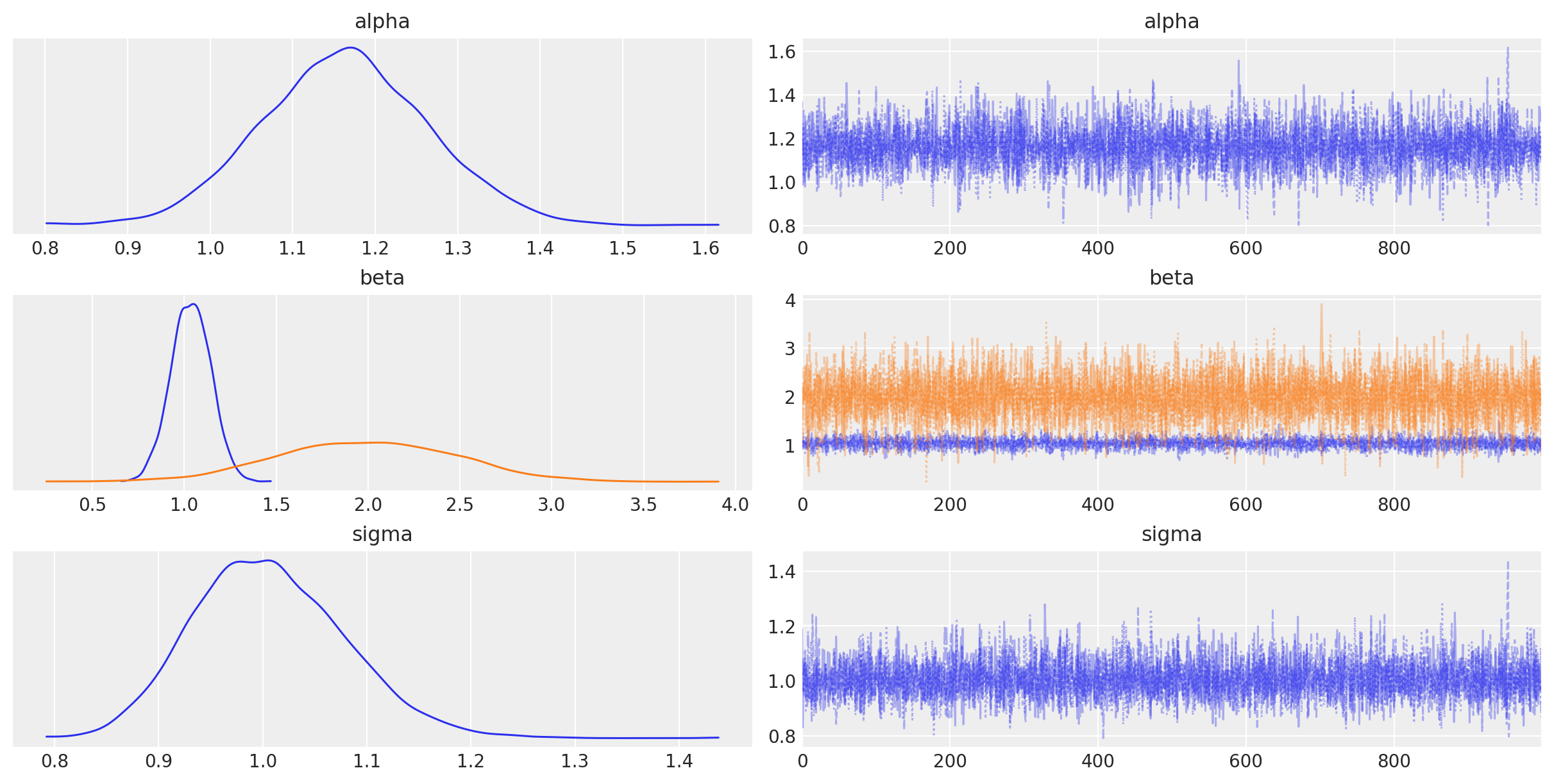
The left column consists of a smoothed histogram (using kernel density estimation) of the marginal posteriors of each stochastic random variable while the right column contains the samples of the Markov chain plotted in sequential order. The beta variable, being vector-valued, produces two density plots and two trace plots, corresponding to both predictor coefficients.
In addition, the summary function provides a text-based output of common posterior statistics:
az.summary(idata, round_to=2)
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| alpha | 1.16 | 0.10 | 0.98 | 1.36 | 0.00 | 0.0 | 5624.84 | 3137.29 | 1.0 |
| beta[0] | 1.04 | 0.11 | 0.84 | 1.24 | 0.00 | 0.0 | 5849.34 | 3324.65 | 1.0 |
| beta[1] | 1.99 | 0.48 | 1.08 | 2.87 | 0.01 | 0.0 | 5965.51 | 3436.28 | 1.0 |
| sigma | 1.01 | 0.07 | 0.87 | 1.14 | 0.00 | 0.0 | 6997.78 | 3191.22 | 1.0 |
Case study 1: Educational Outcomes for Hearing-impaired Children#
As a motivating example, we will use a dataset of educational outcomes for children with hearing impairment. Here, we are interested in determining factors that are associated with better or poorer learning outcomes.
The Data#
This anonymized dataset is taken from the Listening and Spoken Language Data Repository (LSL-DR), an international data repository that tracks the demographics and longitudinal outcomes for children who have hearing loss and are enrolled in programs focused on supporting listening and spoken language development. Researchers are interested in discovering factors related to improvements in educational outcomes within these programs.
There is a suite of available predictors, including:
gender (
male)number of siblings in the household (
siblings)index of family involvement (
family_inv)whether the primary household language is not English (
non_english)presence of a previous disability (
prev_disab)non-white race (
non_white)age at the time of testing (in months,
age_test)whether hearing loss is not severe (
non_severe_hl)whether the subject’s mother obtained a high school diploma or better (
mother_hs)whether the hearing impairment was identified by 3 months of age (
early_ident).
The outcome variable is a standardized test score in one of several learning domains.
test_scores = pd.read_csv(pm.get_data("test_scores.csv"), index_col=0)
test_scores.head()
---------------------------------------------------------------------------
gaierror Traceback (most recent call last)
File ~/Dropbox/Anaconda/anaconda3/envs/8820-env/lib/python3.10/urllib/request.py:1348, in AbstractHTTPHandler.do_open(self, http_class, req, **http_conn_args)
1347 try:
-> 1348 h.request(req.get_method(), req.selector, req.data, headers,
1349 encode_chunked=req.has_header('Transfer-encoding'))
1350 except OSError as err: # timeout error
File ~/Dropbox/Anaconda/anaconda3/envs/8820-env/lib/python3.10/http/client.py:1283, in HTTPConnection.request(self, method, url, body, headers, encode_chunked)
1282 """Send a complete request to the server."""
-> 1283 self._send_request(method, url, body, headers, encode_chunked)
File ~/Dropbox/Anaconda/anaconda3/envs/8820-env/lib/python3.10/http/client.py:1329, in HTTPConnection._send_request(self, method, url, body, headers, encode_chunked)
1328 body = _encode(body, 'body')
-> 1329 self.endheaders(body, encode_chunked=encode_chunked)
File ~/Dropbox/Anaconda/anaconda3/envs/8820-env/lib/python3.10/http/client.py:1278, in HTTPConnection.endheaders(self, message_body, encode_chunked)
1277 raise CannotSendHeader()
-> 1278 self._send_output(message_body, encode_chunked=encode_chunked)
File ~/Dropbox/Anaconda/anaconda3/envs/8820-env/lib/python3.10/http/client.py:1038, in HTTPConnection._send_output(self, message_body, encode_chunked)
1037 del self._buffer[:]
-> 1038 self.send(msg)
1040 if message_body is not None:
1041
1042 # create a consistent interface to message_body
File ~/Dropbox/Anaconda/anaconda3/envs/8820-env/lib/python3.10/http/client.py:976, in HTTPConnection.send(self, data)
975 if self.auto_open:
--> 976 self.connect()
977 else:
File ~/Dropbox/Anaconda/anaconda3/envs/8820-env/lib/python3.10/http/client.py:1448, in HTTPSConnection.connect(self)
1446 "Connect to a host on a given (SSL) port."
-> 1448 super().connect()
1450 if self._tunnel_host:
File ~/Dropbox/Anaconda/anaconda3/envs/8820-env/lib/python3.10/http/client.py:942, in HTTPConnection.connect(self)
941 sys.audit("http.client.connect", self, self.host, self.port)
--> 942 self.sock = self._create_connection(
943 (self.host,self.port), self.timeout, self.source_address)
944 # Might fail in OSs that don't implement TCP_NODELAY
File ~/Dropbox/Anaconda/anaconda3/envs/8820-env/lib/python3.10/socket.py:824, in create_connection(address, timeout, source_address)
823 err = None
--> 824 for res in getaddrinfo(host, port, 0, SOCK_STREAM):
825 af, socktype, proto, canonname, sa = res
File ~/Dropbox/Anaconda/anaconda3/envs/8820-env/lib/python3.10/socket.py:955, in getaddrinfo(host, port, family, type, proto, flags)
954 addrlist = []
--> 955 for res in _socket.getaddrinfo(host, port, family, type, proto, flags):
956 af, socktype, proto, canonname, sa = res
gaierror: [Errno 8] nodename nor servname provided, or not known
During handling of the above exception, another exception occurred:
URLError Traceback (most recent call last)
Cell In[13], line 1
----> 1 test_scores = pd.read_csv(pm.get_data("test_scores.csv"), index_col=0)
2 test_scores.head()
File ~/Dropbox/Anaconda/anaconda3/envs/8820-env/lib/python3.10/site-packages/pymc/data.py:65, in get_data(filename)
53 def get_data(filename):
54 """Returns a BytesIO object for a package data file.
55
56 Parameters
(...)
63 BytesIO of the data
64 """
---> 65 with urllib.request.urlopen(BASE_URL.format(filename=filename)) as handle:
66 content = handle.read()
67 return io.BytesIO(content)
File ~/Dropbox/Anaconda/anaconda3/envs/8820-env/lib/python3.10/urllib/request.py:216, in urlopen(url, data, timeout, cafile, capath, cadefault, context)
214 else:
215 opener = _opener
--> 216 return opener.open(url, data, timeout)
File ~/Dropbox/Anaconda/anaconda3/envs/8820-env/lib/python3.10/urllib/request.py:519, in OpenerDirector.open(self, fullurl, data, timeout)
516 req = meth(req)
518 sys.audit('urllib.Request', req.full_url, req.data, req.headers, req.get_method())
--> 519 response = self._open(req, data)
521 # post-process response
522 meth_name = protocol+"_response"
File ~/Dropbox/Anaconda/anaconda3/envs/8820-env/lib/python3.10/urllib/request.py:536, in OpenerDirector._open(self, req, data)
533 return result
535 protocol = req.type
--> 536 result = self._call_chain(self.handle_open, protocol, protocol +
537 '_open', req)
538 if result:
539 return result
File ~/Dropbox/Anaconda/anaconda3/envs/8820-env/lib/python3.10/urllib/request.py:496, in OpenerDirector._call_chain(self, chain, kind, meth_name, *args)
494 for handler in handlers:
495 func = getattr(handler, meth_name)
--> 496 result = func(*args)
497 if result is not None:
498 return result
File ~/Dropbox/Anaconda/anaconda3/envs/8820-env/lib/python3.10/urllib/request.py:1391, in HTTPSHandler.https_open(self, req)
1390 def https_open(self, req):
-> 1391 return self.do_open(http.client.HTTPSConnection, req,
1392 context=self._context, check_hostname=self._check_hostname)
File ~/Dropbox/Anaconda/anaconda3/envs/8820-env/lib/python3.10/urllib/request.py:1351, in AbstractHTTPHandler.do_open(self, http_class, req, **http_conn_args)
1348 h.request(req.get_method(), req.selector, req.data, headers,
1349 encode_chunked=req.has_header('Transfer-encoding'))
1350 except OSError as err: # timeout error
-> 1351 raise URLError(err)
1352 r = h.getresponse()
1353 except:
URLError: <urlopen error [Errno 8] nodename nor servname provided, or not known>
test_scores["score"].hist();
# Dropping missing values is a very bad idea in general, but we do so here for simplicity
X = test_scores.dropna().astype(float)
y = X.pop("score")
# Standardize the features
X -= X.mean()
X /= X.std()
N, D = X.shape
The Model#
This is a more realistic problem than the first regression example, as we are now dealing with a multivariate regression model. However, while there are several potential predictors in the LSL-DR dataset, it is difficult a priori to determine which ones are relevant for constructing an effective statistical model. There are a number of approaches for conducting variable selection, but a popular automated method is regularization, whereby ineffective covariates are shrunk towards zero via regularization (a form of penalization) if they do not contribute to predicting outcomes.
You may have heard of regularization from machine learning or classical statistics applications, where methods like the lasso or ridge regression shrink parameters towards zero by applying a penalty to the size of the regression parameters. In a Bayesian context, we apply an appropriate prior distribution to the regression coefficients. One such prior is the hierarchical regularized horseshoe, which uses two regularization strategies, one global and a set of local parameters, one for each coefficient. The key to making this work is by selecting a long-tailed distribution as the shrinkage priors, which allows some to be nonzero, while pushing the rest towards zero.
The horeshoe prior for each regression coefficient \(\beta_i\) looks like this:
where \(\sigma\) is the prior on the error standard deviation that will also be used for the model likelihood. Here, \(\tau\) is the global shrinkage parameter and \(\tilde{\lambda}_i\) is the local shrinkage parameter. Let’s start global: for the prior on \(\tau\) we will use a Half-StudentT distribution, which is a reasonable choice becuase it is heavy-tailed.
One catch is that the parameterization of the prior requires a pre-specified value \(D_0\), which represents the true number of non-zero coefficients. Fortunately, a reasonable guess at this value is all that is required, and it need only be within an order of magnitude of the true number. Let’s use half the number of predictors as our guess:
D0 = int(D / 2)
Meanwhile, the local shrinkage parameters are defined by the ratio:
To complete this specification, we need priors on \(\lambda_i\) and \(c\); as with the global shrinkage, we use a long-tailed \(\textrm{Half-StudentT}_5(1)\) on the \(\lambda_i\). We need \(c^2\) to be strictly positive, but not necessarily long-tailed, so an inverse gamma prior on \(c^2\), \(c^2 \sim \textrm{InverseGamma}(1, 1)\) fits the bill.
Finally, to allow the NUTS sampler to sample the \(\beta_i\) more efficiently, we will re-parameterize it as follows:
You will run into this reparameterization a lot in practice.
Model Specification#
Specifying the model in PyMC mirrors its statistical specification. This model employs a couple of new distributions: the HalfStudentT distribution for the \(\tau\) and \(\lambda\) priors, and the InverseGamma distribution for the \(c^2\) variable.
In PyMC, variables with purely positive priors like InverseGamma are transformed with a log transform. This makes sampling more robust. Behind the scenes, a variable in the unconstrained space (named <variable-name>_log) is added to the model for sampling. Variables with priors that constrain them on two sides, like Beta or Uniform, are also transformed to be unconstrained but with a log odds transform.
We are also going to take advantage of named dimensions in PyMC and ArviZ by passing the input variable names into the model as coordinates called “predictors”. This will allow us to pass this vector of names as a replacement for the shape integer argument in the vector-valued parameters. The model will then associate the appropriate name with each latent parameter that it is estimating. This is a little more work to set up, but will pay dividends later when we are working with our model output.
Let’s encode this model in PyMC:
import pytensor.tensor as at
with pm.Model(coords={"predictors": X.columns.values}) as test_score_model:
# Prior on error SD
sigma = pm.HalfNormal("sigma", 25)
# Global shrinkage prior
tau = pm.HalfStudentT("tau", 2, D0 / (D - D0) * sigma / np.sqrt(N))
# Local shrinkage prior
lam = pm.HalfStudentT("lam", 5, dims="predictors")
c2 = pm.InverseGamma("c2", 1, 1)
z = pm.Normal("z", 0.0, 1.0, dims="predictors")
# Shrunken coefficients
beta = pm.Deterministic(
"beta", z * tau * lam * at.sqrt(c2 / (c2 + tau**2 * lam**2)), dims="predictors"
)
# No shrinkage on intercept
beta0 = pm.Normal("beta0", 100, 25.0)
scores = pm.Normal("scores", beta0 + at.dot(X.values, beta), sigma, observed=y.values)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[14], line 3
1 import pytensor.tensor as at
----> 3 with pm.Model(coords={"predictors": X.columns.values}) as test_score_model:
4 # Prior on error SD
5 sigma = pm.HalfNormal("sigma", 25)
7 # Global shrinkage prior
NameError: name 'X' is not defined
Notice that we have wrapped the calculation of beta in a Deterministic PyMC class. You can read more about this in detail below, but this ensures that the values of this deterministic variable is retained in the sample trace.
Also note that we have declared the Model name test_score_model in the first occurrence of the context manager, rather than splitting it into two lines, as we did for the first example.
Once the model is complete, we can look at its structure using GraphViz, which plots the model graph. It’s useful to ensure that the relationships in the model you have coded are correct, as it’s easy to make coding mistakes.
pm.model_to_graphviz(test_score_model)
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
File ~/Dropbox/Anaconda/anaconda3/envs/pymc_env/lib/python3.11/site-packages/graphviz/backend/execute.py:79, in run_check(cmd, input_lines, encoding, quiet, **kwargs)
78 kwargs['stdout'] = kwargs['stderr'] = subprocess.PIPE
---> 79 proc = _run_input_lines(cmd, input_lines, kwargs=kwargs)
80 else:
File ~/Dropbox/Anaconda/anaconda3/envs/pymc_env/lib/python3.11/site-packages/graphviz/backend/execute.py:99, in _run_input_lines(cmd, input_lines, kwargs)
98 def _run_input_lines(cmd, input_lines, *, kwargs):
---> 99 popen = subprocess.Popen(cmd, stdin=subprocess.PIPE, **kwargs)
101 stdin_write = popen.stdin.write
File ~/Dropbox/Anaconda/anaconda3/envs/pymc_env/lib/python3.11/subprocess.py:1026, in Popen.__init__(self, args, bufsize, executable, stdin, stdout, stderr, preexec_fn, close_fds, shell, cwd, env, universal_newlines, startupinfo, creationflags, restore_signals, start_new_session, pass_fds, user, group, extra_groups, encoding, errors, text, umask, pipesize, process_group)
1023 self.stderr = io.TextIOWrapper(self.stderr,
1024 encoding=encoding, errors=errors)
-> 1026 self._execute_child(args, executable, preexec_fn, close_fds,
1027 pass_fds, cwd, env,
1028 startupinfo, creationflags, shell,
1029 p2cread, p2cwrite,
1030 c2pread, c2pwrite,
1031 errread, errwrite,
1032 restore_signals,
1033 gid, gids, uid, umask,
1034 start_new_session, process_group)
1035 except:
1036 # Cleanup if the child failed starting.
File ~/Dropbox/Anaconda/anaconda3/envs/pymc_env/lib/python3.11/subprocess.py:1950, in Popen._execute_child(self, args, executable, preexec_fn, close_fds, pass_fds, cwd, env, startupinfo, creationflags, shell, p2cread, p2cwrite, c2pread, c2pwrite, errread, errwrite, restore_signals, gid, gids, uid, umask, start_new_session, process_group)
1949 err_msg = os.strerror(errno_num)
-> 1950 raise child_exception_type(errno_num, err_msg, err_filename)
1951 raise child_exception_type(err_msg)
FileNotFoundError: [Errno 2] No such file or directory: PosixPath('dot')
The above exception was the direct cause of the following exception:
ExecutableNotFound Traceback (most recent call last)
File ~/Dropbox/Anaconda/anaconda3/envs/pymc_env/lib/python3.11/site-packages/IPython/core/formatters.py:974, in MimeBundleFormatter.__call__(self, obj, include, exclude)
971 method = get_real_method(obj, self.print_method)
973 if method is not None:
--> 974 return method(include=include, exclude=exclude)
975 return None
976 else:
File ~/Dropbox/Anaconda/anaconda3/envs/pymc_env/lib/python3.11/site-packages/graphviz/jupyter_integration.py:98, in JupyterIntegration._repr_mimebundle_(self, include, exclude, **_)
96 include = set(include) if include is not None else {self._jupyter_mimetype}
97 include -= set(exclude or [])
---> 98 return {mimetype: getattr(self, method_name)()
99 for mimetype, method_name in MIME_TYPES.items()
100 if mimetype in include}
File ~/Dropbox/Anaconda/anaconda3/envs/pymc_env/lib/python3.11/site-packages/graphviz/jupyter_integration.py:98, in <dictcomp>(.0)
96 include = set(include) if include is not None else {self._jupyter_mimetype}
97 include -= set(exclude or [])
---> 98 return {mimetype: getattr(self, method_name)()
99 for mimetype, method_name in MIME_TYPES.items()
100 if mimetype in include}
File ~/Dropbox/Anaconda/anaconda3/envs/pymc_env/lib/python3.11/site-packages/graphviz/jupyter_integration.py:112, in JupyterIntegration._repr_image_svg_xml(self)
110 def _repr_image_svg_xml(self) -> str:
111 """Return the rendered graph as SVG string."""
--> 112 return self.pipe(format='svg', encoding=SVG_ENCODING)
File ~/Dropbox/Anaconda/anaconda3/envs/pymc_env/lib/python3.11/site-packages/graphviz/piping.py:104, in Pipe.pipe(self, format, renderer, formatter, neato_no_op, quiet, engine, encoding)
55 def pipe(self,
56 format: typing.Optional[str] = None,
57 renderer: typing.Optional[str] = None,
(...)
61 engine: typing.Optional[str] = None,
62 encoding: typing.Optional[str] = None) -> typing.Union[bytes, str]:
63 """Return the source piped through the Graphviz layout command.
64
65 Args:
(...)
102 '<?xml version='
103 """
--> 104 return self._pipe_legacy(format,
105 renderer=renderer,
106 formatter=formatter,
107 neato_no_op=neato_no_op,
108 quiet=quiet,
109 engine=engine,
110 encoding=encoding)
File ~/Dropbox/Anaconda/anaconda3/envs/pymc_env/lib/python3.11/site-packages/graphviz/_tools.py:171, in deprecate_positional_args.<locals>.decorator.<locals>.wrapper(*args, **kwargs)
162 wanted = ', '.join(f'{name}={value!r}'
163 for name, value in deprecated.items())
164 warnings.warn(f'The signature of {func.__name__} will be reduced'
165 f' to {supported_number} positional args'
166 f' {list(supported)}: pass {wanted}'
167 ' as keyword arg(s)',
168 stacklevel=stacklevel,
169 category=category)
--> 171 return func(*args, **kwargs)
File ~/Dropbox/Anaconda/anaconda3/envs/pymc_env/lib/python3.11/site-packages/graphviz/piping.py:121, in Pipe._pipe_legacy(self, format, renderer, formatter, neato_no_op, quiet, engine, encoding)
112 @_tools.deprecate_positional_args(supported_number=2)
113 def _pipe_legacy(self,
114 format: typing.Optional[str] = None,
(...)
119 engine: typing.Optional[str] = None,
120 encoding: typing.Optional[str] = None) -> typing.Union[bytes, str]:
--> 121 return self._pipe_future(format,
122 renderer=renderer,
123 formatter=formatter,
124 neato_no_op=neato_no_op,
125 quiet=quiet,
126 engine=engine,
127 encoding=encoding)
File ~/Dropbox/Anaconda/anaconda3/envs/pymc_env/lib/python3.11/site-packages/graphviz/piping.py:149, in Pipe._pipe_future(self, format, renderer, formatter, neato_no_op, quiet, engine, encoding)
146 if encoding is not None:
147 if codecs.lookup(encoding) is codecs.lookup(self.encoding):
148 # common case: both stdin and stdout need the same encoding
--> 149 return self._pipe_lines_string(*args, encoding=encoding, **kwargs)
150 try:
151 raw = self._pipe_lines(*args, input_encoding=self.encoding, **kwargs)
File ~/Dropbox/Anaconda/anaconda3/envs/pymc_env/lib/python3.11/site-packages/graphviz/backend/piping.py:212, in pipe_lines_string(engine, format, input_lines, encoding, renderer, formatter, neato_no_op, quiet)
206 cmd = dot_command.command(engine, format,
207 renderer=renderer,
208 formatter=formatter,
209 neato_no_op=neato_no_op)
210 kwargs = {'input_lines': input_lines, 'encoding': encoding}
--> 212 proc = execute.run_check(cmd, capture_output=True, quiet=quiet, **kwargs)
213 return proc.stdout
File ~/Dropbox/Anaconda/anaconda3/envs/pymc_env/lib/python3.11/site-packages/graphviz/backend/execute.py:84, in run_check(cmd, input_lines, encoding, quiet, **kwargs)
82 except OSError as e:
83 if e.errno == errno.ENOENT:
---> 84 raise ExecutableNotFound(cmd) from e
85 raise
87 if not quiet and proc.stderr:
ExecutableNotFound: failed to execute PosixPath('dot'), make sure the Graphviz executables are on your systems' PATH
<graphviz.graphs.Digraph at 0x17fb66d90>
Before we proceed further, let’s see what the model does before it sees any data. We can conduct prior predictive sampling to generate simulated data from the model. Then, let’s compare these simulations to the actual test scores in the dataset.
with test_score_model:
prior_samples = pm.sample_prior_predictive(100)
Sampling: [beta0, c2, lam, scores, sigma, tau, z]
az.plot_dist(
test_scores["score"].values,
kind="hist",
color="C1",
hist_kwargs=dict(alpha=0.6),
label="observed",
)
az.plot_dist(
prior_samples.prior_predictive["scores"],
kind="hist",
hist_kwargs=dict(alpha=0.6),
label="simulated",
)
plt.xticks(rotation=45);
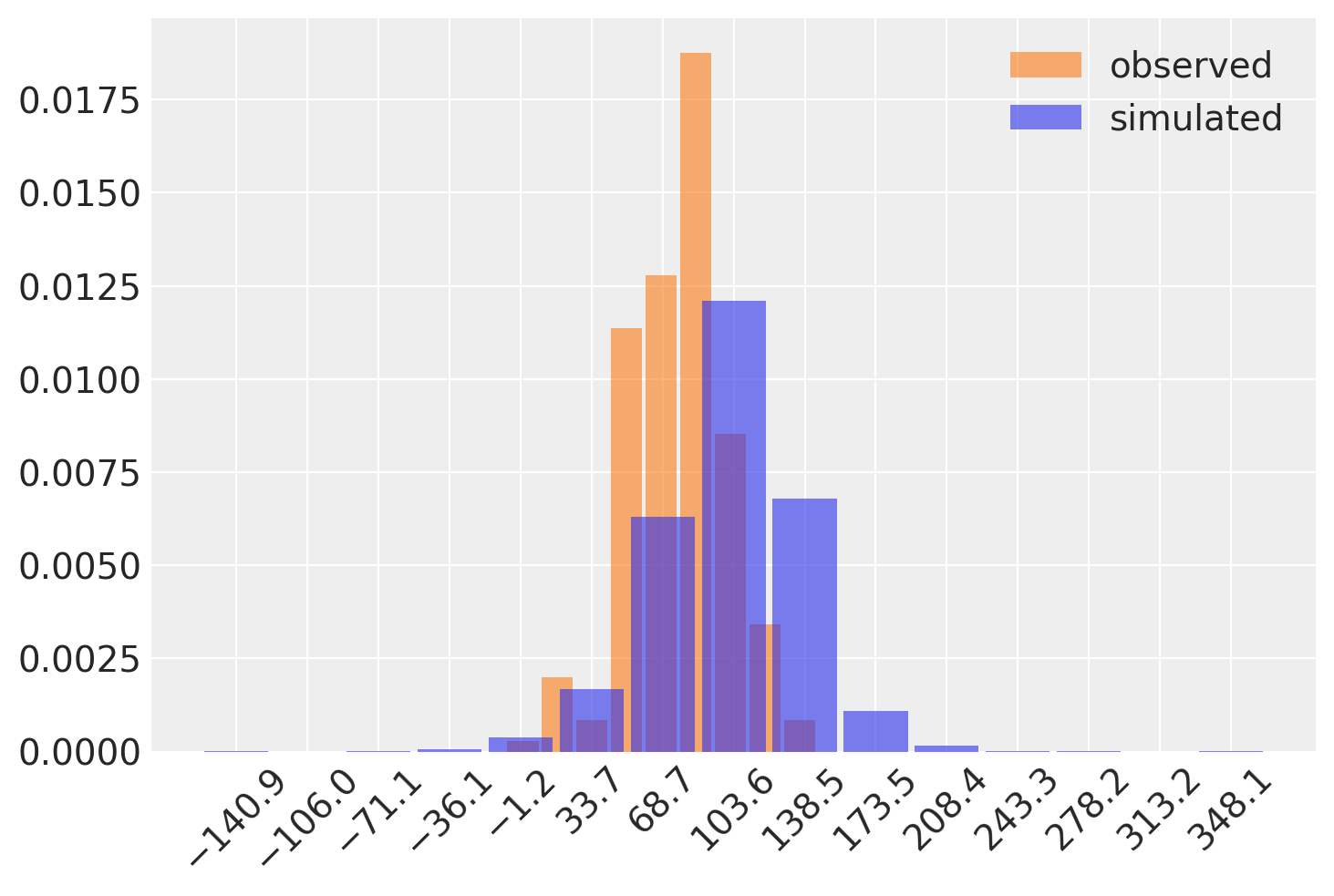
How do we know if this is reasonable or not? This requires some domain knowledge of the problem. Here, we are trying to predict the outcomes of test scores. If our model was predicting values in the thousands, or lots of negative values, while excluding scores that are plausible, then we have misspecified our model. You can see here that the support of the distribution of simulated data completely overlaps the support of the observed distribution of scores; this is a good sign! There are a few negative values and a few that are probably too large to be plausible, but nothing to worry about.
Model Fitting#
Now for the easy part: PyMC’s “Inference Button” is the call to sample. We will let this model tune for a little longer than the default value (1000 iterations). This gives the NUTS sampler a little more time to tune itself adequately.
with test_score_model:
idata = pm.sample(1000, tune=2000, random_seed=42)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [sigma, tau, lam, c2, z, beta0]
Sampling 4 chains for 2_000 tune and 1_000 draw iterations (8_000 + 4_000 draws total) took 37 seconds.
There were 1 divergences after tuning. Increase `target_accept` or reparameterize.
Notice that we have a few warnings here about divergences. These are samples where NUTS was not able to make a valid move across the posterior distribution, so the resulting points are probably not representative samples from the posterior. There aren’t many in this example, so it’s nothing to worry about, but let’s go ahead and follow the advice and increase target_accept from its default value of 0.9 to 0.99.
with test_score_model:
idata = pm.sample(1000, tune=2000, random_seed=42, target_accept=0.99)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [sigma, tau, lam, c2, z, beta0]
Sampling 4 chains for 2_000 tune and 1_000 draw iterations (8_000 + 4_000 draws total) took 54 seconds.
Since the target acceptance rate is larger, the algorithm is being more conservative with its leapfrog steps, making them smaller. The price we pay for this is that each sample takes longer to complete. However, the warnings are now gone, and we have a clean posterior sample!
Model Checking#
A simple first step in model checking is to visually inspect our samples by looking at the traceplot for the univariate latent parameters to check for obvious problems. These names can be passed to plot_trace in the var_names argument.
az.plot_trace(idata, var_names=["tau", "sigma", "c2"]);
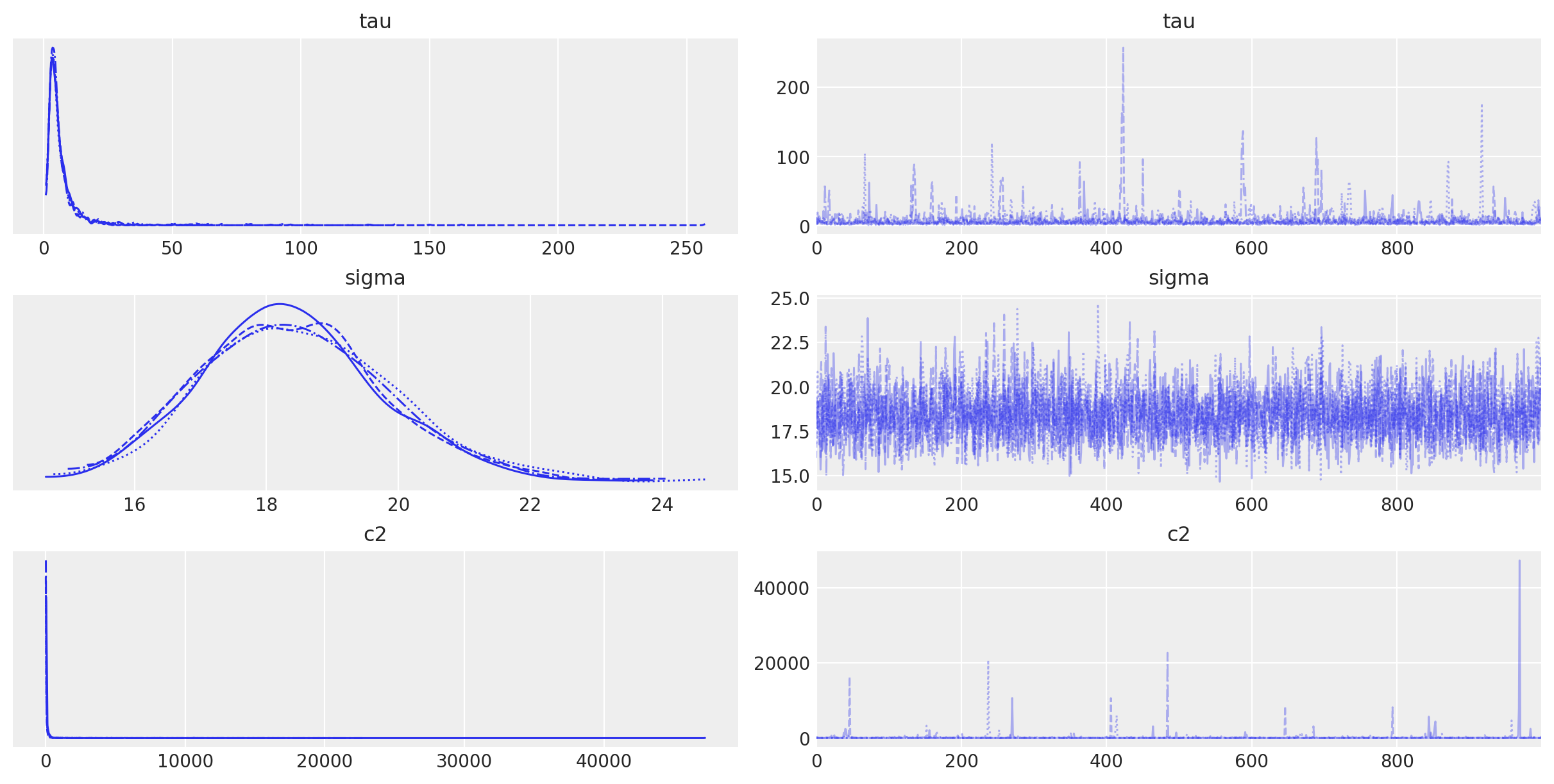
Do these look okay? Well, each of the densities on the left side for each parameter look pretty similar to the others, which means they have converged to the same posterior distribution (be it the correct one or not). The homogeneity of the trace plots on the right are also a good sign; there is no trend or pattern to the time series of sampled values. Note that c2 and tau occasionally sample extreme values, but this is expected from heavy-tailed distributions.
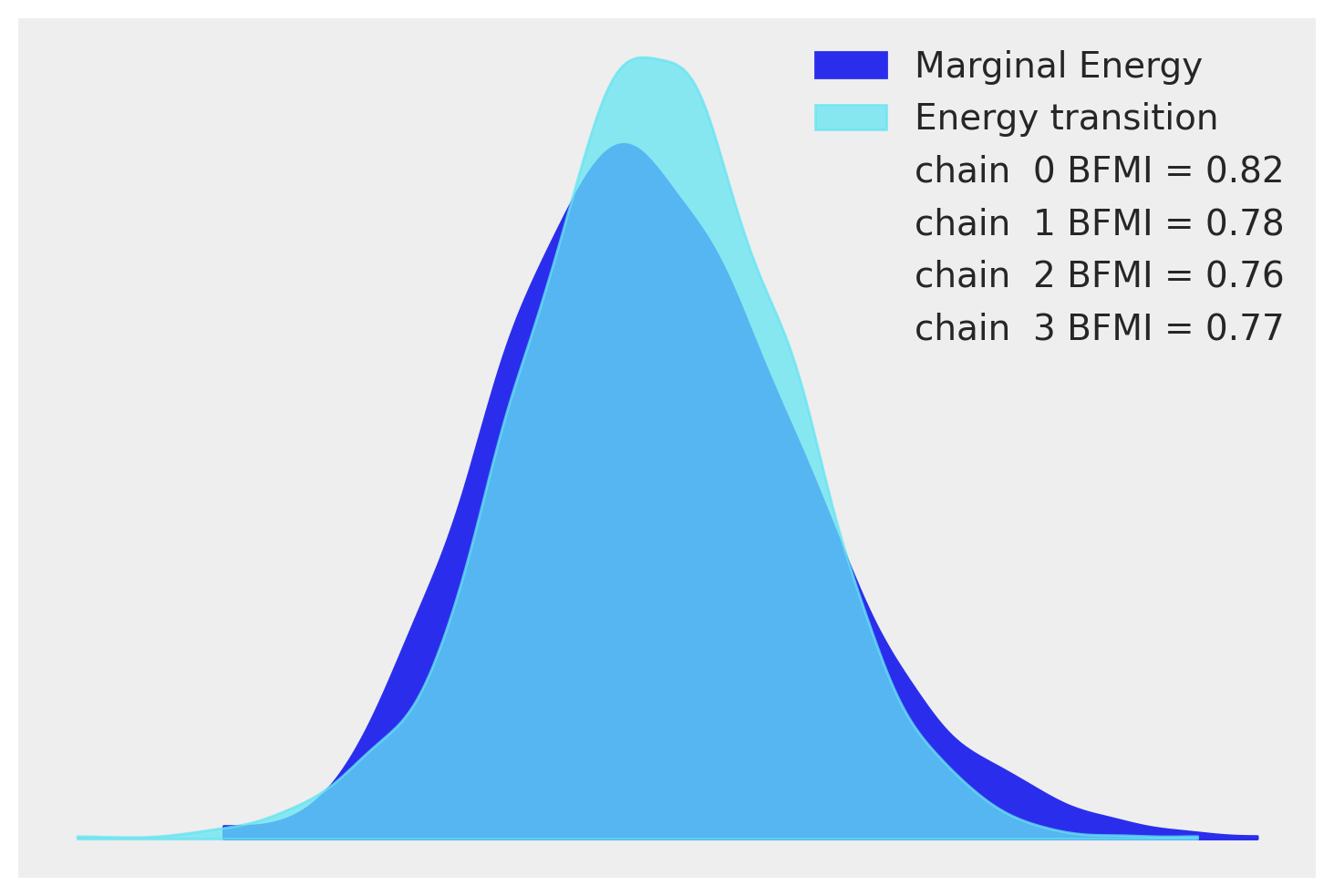
The next easy model-checking step is to see if the NUTS sampler performed as expected. An energy plot is a way of checking if the NUTS algorithm was able to adequately explore the posterior distribution. If it was not, one runs the risk of biased posterior estimates when parts of the posterior are not visited with adequate frequency. The plot shows two density estimates: one is the marginal energy distribution of the sampling run and the other is the distribution of the energy transitions between steps. This is all a little abstract, but all we are looking for is for the distributions to be similar to one another. Ours does not look too bad.
az.plot_energy(idata);
Ultimately, we are interested in the estimates of beta, the set of predictor coefficients. Passing beta to plot_trace would generate a very crowded plot, so we will use plot_forest instead, which is designed to handle vector-valued parameters.
az.plot_forest(idata, var_names=["beta"], combined=True, hdi_prob=0.95, r_hat=True);
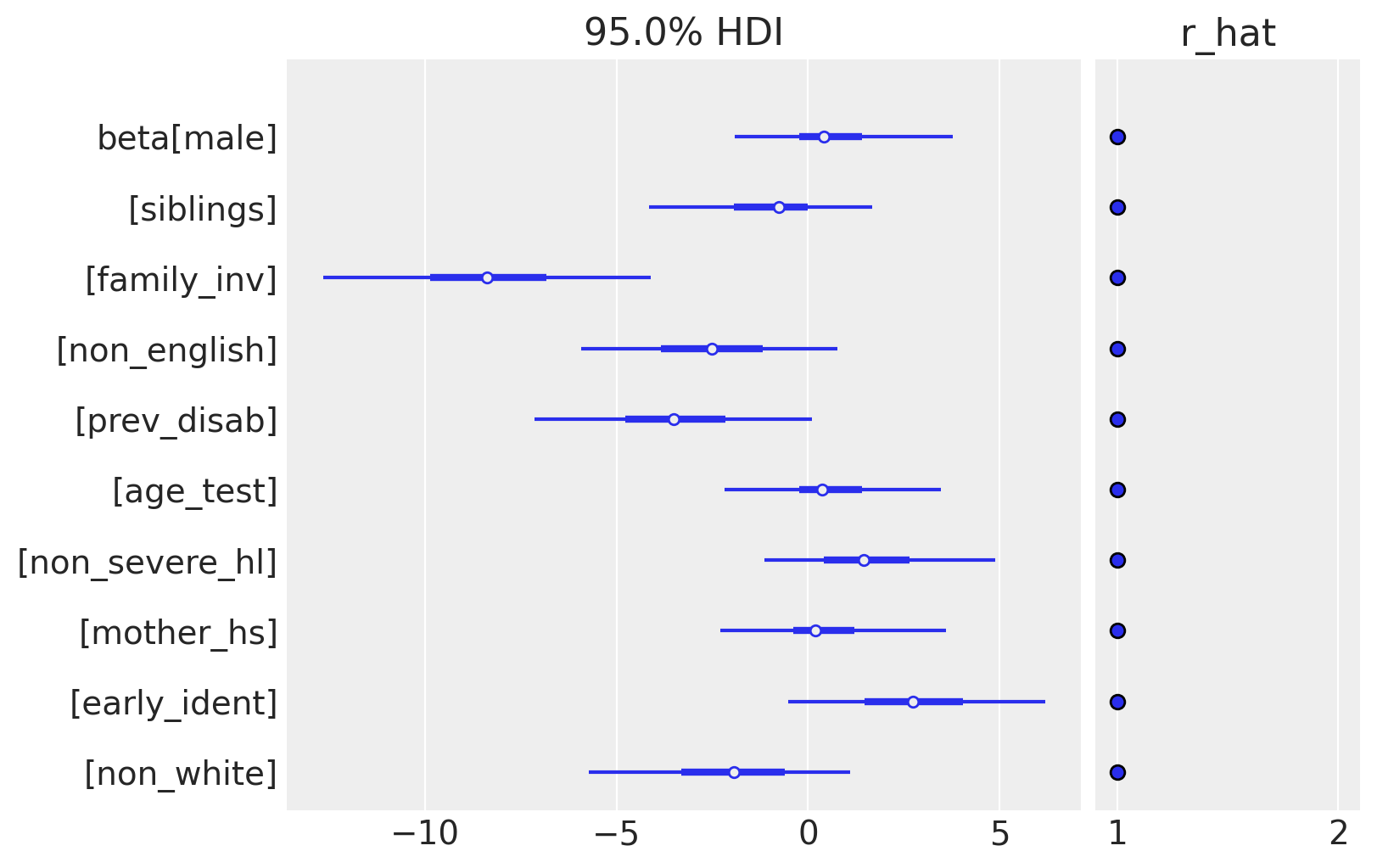
The posterior distribution of coefficients reveal some factors that appear to be important in predicting test scores. Family involvement (family_inv) is large and negative, meaning a larger score (which is related to poorer involvement) results in much worse test scores. On the other end, early identification of hearing impairment is positive, meaning that detecting a problem early results in better educational outcomes down the road, which is also intuitive. Notice that other variables, notably gender (male), age at testing (age_test), and the mother’s educational status (mother_hs) have all been shrunk essentially to zero.
Case study 2: Coal mining disasters#
Consider the following time series of recorded coal mining disasters in the UK from 1851 to 1962 (Jarrett, 1979). The number of disasters is thought to have been affected by changes in safety regulations during this period. Unfortunately, we also have a pair of years with missing data, identified as missing by a nan in the pandas Series. These missing values will be automatically imputed by PyMC.
Next we will build a model for this series and attempt to estimate when the change occurred. At the same time, we will see how to handle missing data, use multiple samplers and sample from discrete random variables.
# fmt: off
disaster_data = pd.Series(
[4, 5, 4, 0, 1, 4, 3, 4, 0, 6, 3, 3, 4, 0, 2, 6,
3, 3, 5, 4, 5, 3, 1, 4, 4, 1, 5, 5, 3, 4, 2, 5,
2, 2, 3, 4, 2, 1, 3, np.nan, 2, 1, 1, 1, 1, 3, 0, 0,
1, 0, 1, 1, 0, 0, 3, 1, 0, 3, 2, 2, 0, 1, 1, 1,
0, 1, 0, 1, 0, 0, 0, 2, 1, 0, 0, 0, 1, 1, 0, 2,
3, 3, 1, np.nan, 2, 1, 1, 1, 1, 2, 4, 2, 0, 0, 1, 4,
0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1]
)
# fmt: on
years = np.arange(1851, 1962)
plt.plot(years, disaster_data, "o", markersize=8, alpha=0.4)
plt.ylabel("Disaster count")
plt.xlabel("Year");
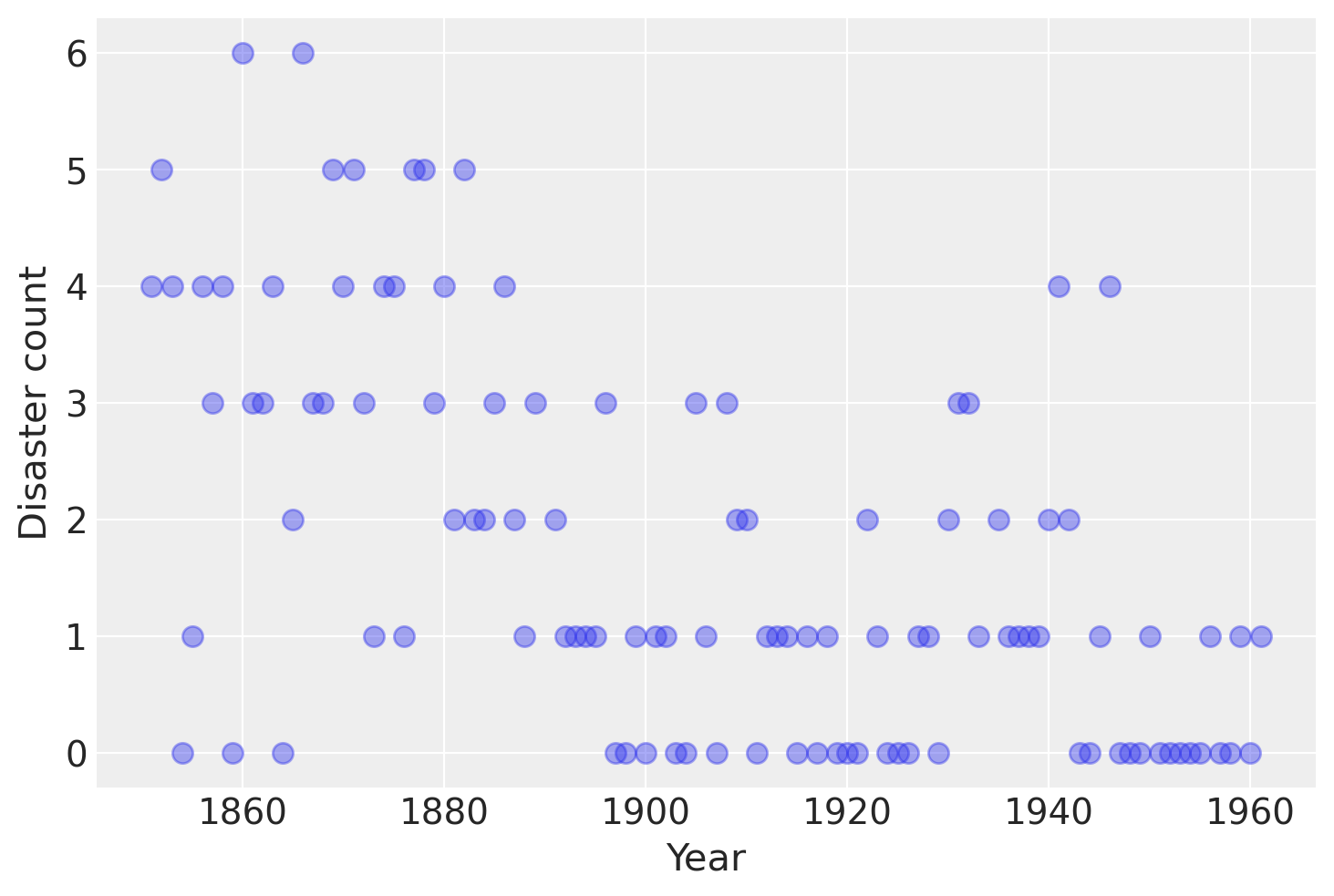
Occurrences of disasters in the time series is thought to follow a Poisson process with a large rate parameter in the early part of the time series, and from one with a smaller rate in the later part. We are interested in locating the change point in the series, which is perhaps related to changes in mining safety regulations.
In our model,
the parameters are defined as follows:
\(D_t\): The number of disasters in year \(t\)
\(r_t\): The rate parameter of the Poisson distribution of disasters in year \(t\).
\(s\): The year in which the rate parameter changes (the switchpoint).
\(e\): The rate parameter before the switchpoint \(s\).
\(l\): The rate parameter after the switchpoint \(s\).
\(t_l\), \(t_h\): The lower and upper boundaries of year \(t\).
This model is built much like our previous models. The major differences are the introduction of discrete variables with the Poisson and discrete-uniform priors and the novel form of the deterministic random variable rate.
with pm.Model() as disaster_model:
switchpoint = pm.DiscreteUniform("switchpoint", lower=years.min(), upper=years.max())
# Priors for pre- and post-switch rates number of disasters
early_rate = pm.Exponential("early_rate", 1.0)
late_rate = pm.Exponential("late_rate", 1.0)
# Allocate appropriate Poisson rates to years before and after current
rate = pm.math.switch(switchpoint >= years, early_rate, late_rate)
disasters = pm.Poisson("disasters", rate, observed=disaster_data)
/Users/furnstah/Dropbox/Anaconda/anaconda3/envs/pymc_env/lib/python3.11/site-packages/pymc/model/core.py:1309: RuntimeWarning: invalid value encountered in cast
data = convert_observed_data(data).astype(rv_var.dtype)
/Users/furnstah/Dropbox/Anaconda/anaconda3/envs/pymc_env/lib/python3.11/site-packages/pymc/model/core.py:1323: ImputationWarning: Data in disasters contains missing values and will be automatically imputed from the sampling distribution.
warnings.warn(impute_message, ImputationWarning)
The logic for the rate random variable,
rate = switch(switchpoint >= year, early_rate, late_rate)
is implemented using switch, a function that works like an if statement. It uses the first argument to switch between the next two arguments.
Missing values are handled transparently by passing a NumPy MaskedArray or a DataFrame with NaN values to the observed argument when creating an observed stochastic random variable. Behind the scenes, another random variable, disasters.missing_values is created to model the missing values.
Unfortunately, because they are discrete variables and thus have no meaningful gradient, we cannot use NUTS for sampling switchpoint or the missing disaster observations. Instead, we will sample using a Metropolis step method, which implements adaptive Metropolis-Hastings, because it is designed to handle discrete values. PyMC automatically assigns the correct sampling algorithms.
with disaster_model:
idata = pm.sample(10000)
Multiprocess sampling (4 chains in 4 jobs)
CompoundStep
>CompoundStep
>>Metropolis: [switchpoint]
>>Metropolis: [disasters_unobserved]
>NUTS: [early_rate, late_rate]
Sampling 4 chains for 1_000 tune and 10_000 draw iterations (4_000 + 40_000 draws total) took 40 seconds.
In the trace plot below we can see that there’s about a 10 year span that’s plausible for a significant change in safety, but a 5 year span that contains most of the probability mass. The distribution is jagged because of the jumpy relationship between the year switchpoint and the likelihood; the jaggedness is not due to sampling error.
axes_arr = az.plot_trace(idata)
plt.draw()
for ax in axes_arr.flatten():
if ax.get_title() == "switchpoint":
labels = [label.get_text() for label in ax.get_xticklabels()]
ax.set_xticklabels(labels, rotation=45, ha="right")
break
plt.draw()
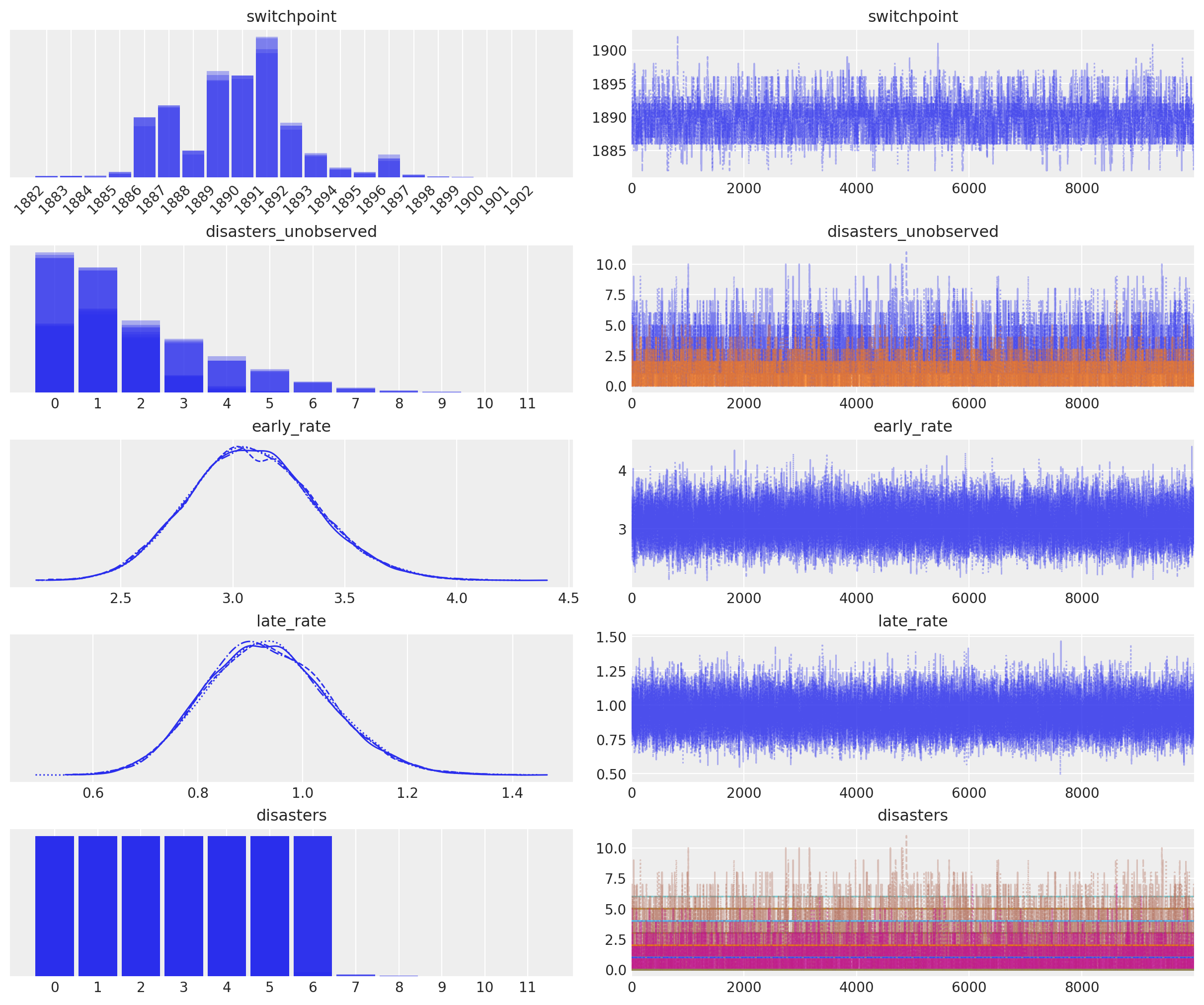
Note that the rate random variable does not appear in the trace. That is fine in this case, because it is not of interest in itself. Remember from the previous example, we would trace the variable by wrapping it in a Deterministic class, and giving it a name.
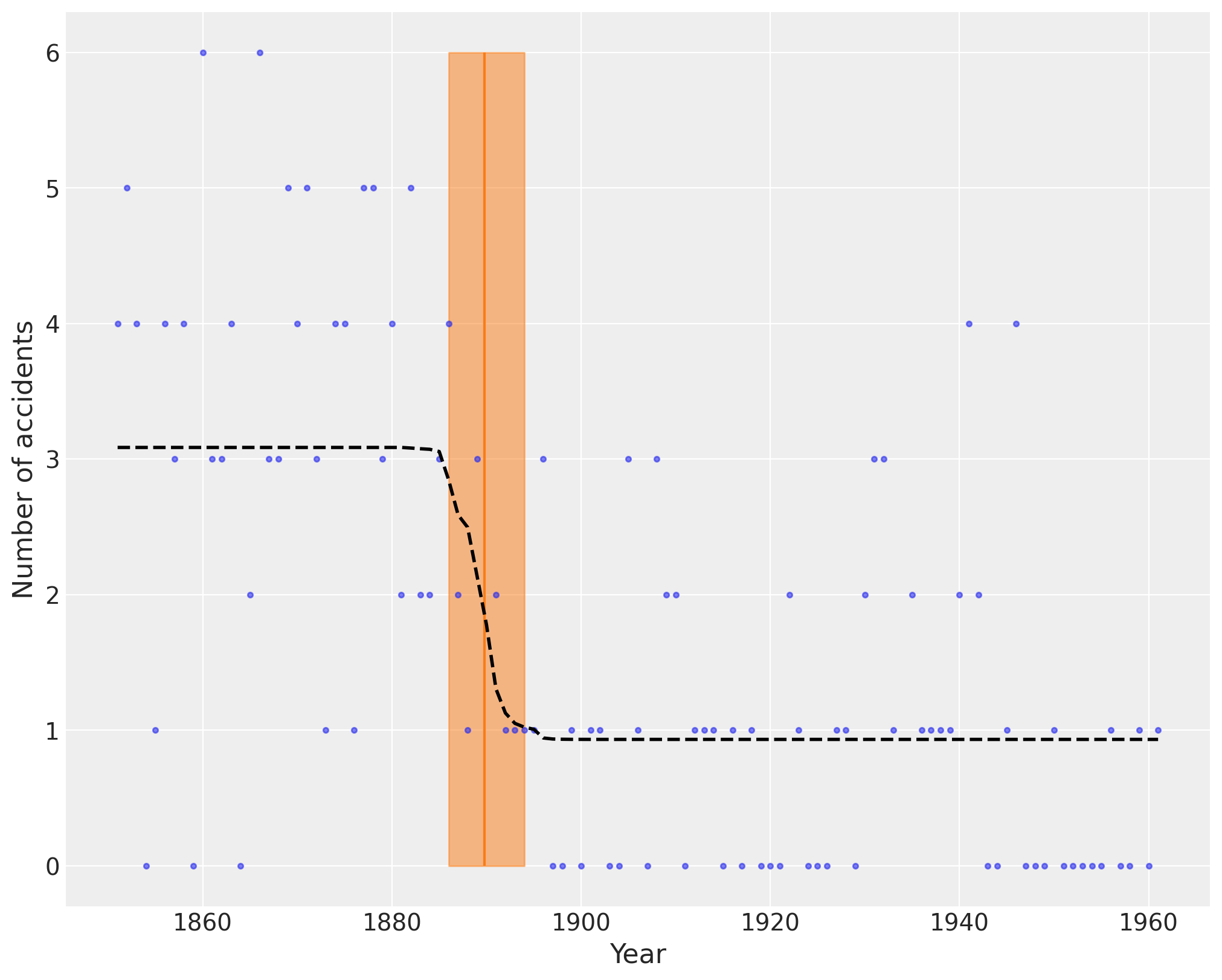
The following plot shows the switch point as an orange vertical line, together with its highest posterior density (HPD) as a semitransparent band. The dashed black line shows the accident rate.
plt.figure(figsize=(10, 8))
plt.plot(years, disaster_data, ".", alpha=0.6)
plt.ylabel("Number of accidents", fontsize=16)
plt.xlabel("Year", fontsize=16)
trace = idata.posterior.stack(draws=("chain", "draw"))
plt.vlines(trace["switchpoint"].mean(), disaster_data.min(), disaster_data.max(), color="C1")
average_disasters = np.zeros_like(disaster_data, dtype="float")
for i, year in enumerate(years):
idx = year < trace["switchpoint"]
average_disasters[i] = np.mean(np.where(idx, trace["early_rate"], trace["late_rate"]))
sp_hpd = az.hdi(idata, var_names=["switchpoint"])["switchpoint"].values
plt.fill_betweenx(
y=[disaster_data.min(), disaster_data.max()],
x1=sp_hpd[0],
x2=sp_hpd[1],
alpha=0.5,
color="C1",
)
plt.plot(years, average_disasters, "k--", lw=2);
Arbitrary deterministics#
Due to its reliance on PyTensor, PyMC provides many mathematical functions and operators for transforming random variables into new random variables. However, the library of functions in PyTensor is not exhaustive, therefore PyTensor and PyMC provide functionality for creating arbitrary functions in pure Python, and including these functions in PyMC models. This is supported with the as_op function decorator.
PyTensor needs to know the types of the inputs and outputs of a function, which are specified for as_op by itypes for inputs and otypes for outputs.
from pytensor.compile.ops import as_op
@as_op(itypes=[at.lscalar], otypes=[at.lscalar])
def crazy_modulo3(value):
if value > 0:
return value % 3
else:
return (-value + 1) % 3
with pm.Model() as model_deterministic:
a = pm.Poisson("a", 1)
b = crazy_modulo3(a)
An important drawback of this approach is that it is not possible for pytensor to inspect these functions in order to compute the gradient required for the Hamiltonian-based samplers. Therefore, it is not possible to use the HMC or NUTS samplers for a model that uses such an operator. However, it is possible to add a gradient if we inherit from Op instead of using as_op. The PyMC example set includes a more elaborate example of the usage of as_op.
Arbitrary distributions#
Similarly, the library of statistical distributions in PyMC is not exhaustive, but PyMC allows for the creation of user-defined functions for an arbitrary probability distribution. For simple statistical distributions, the DensityDist class takes as an argument any function that calculates a log-probability \(log(p(x))\). This function may employ other random variables in its calculation. Here is an example inspired by a blog post by Jake Vanderplas on which priors to use for a linear regression (Vanderplas, 2014).
import pytensor.tensor as at
with pm.Model() as model:
alpha = pm.Uniform('intercept', -100, 100)
# Create custom densities
beta = pm.DensityDist('beta', logp=lambda value: -1.5 * at.log(1 + value**2))
eps = pm.DensityDist('eps', logp=lambda value: -at.log(at.abs_(value)))
# Create likelihood
like = pm.Normal('y_est', mu=alpha + beta * X, sigma=eps, observed=Y)
For more complex distributions, one can create a subclass of Continuous or Discrete and provide the custom logp function, as required. This is how the built-in distributions in PyMC are specified. As an example, fields like psychology and astrophysics have complex likelihood functions for particular processes that may require numerical approximation.
Implementing the beta variable above as a Continuous subclass is shown below, along with an associated RandomVariable object, an instance of which becomes an attribute of the distribution.
class BetaRV(at.random.op.RandomVariable):
name = "beta"
ndim_supp = 0
ndims_params = []
dtype = "floatX"
@classmethod
def rng_fn(cls, rng, size):
raise NotImplementedError("Cannot sample from beta variable")
beta = BetaRV()
class Beta(pm.Continuous):
rv_op = beta
@classmethod
def dist(cls, mu=0, **kwargs):
mu = at.as_tensor_variable(mu)
return super().dist([mu], **kwargs)
def logp(self, value):
mu = self.mu
return beta_logp(value - mu)
def beta_logp(value):
return -1.5 * at.log(1 + (value) ** 2)
with pm.Model() as model:
beta = Beta("beta", mu=0)
If your logp can not be expressed in PyTensor, you can decorate the function with as_op as follows: @as_op(itypes=[at.dscalar], otypes=[at.dscalar]). Note, that this will create a blackbox Python function that will be much slower and not provide the gradients necessary for e.g. NUTS.
Discussion#
Probabilistic programming is an emerging paradigm in statistical learning, of which Bayesian modeling is an important sub-discipline. The signature characteristics of probabilistic programming–specifying variables as probability distributions and conditioning variables on other variables and on observations–makes it a powerful tool for building models in a variety of settings, and over a range of model complexity. Accompanying the rise of probabilistic programming has been a burst of innovation in fitting methods for Bayesian models that represent notable improvement over existing MCMC methods. Yet, despite this expansion, there are few software packages available that have kept pace with the methodological innovation, and still fewer that allow non-expert users to implement models.
PyMC provides a probabilistic programming platform for quantitative researchers to implement statistical models flexibly and succinctly. A large library of statistical distributions and several pre-defined fitting algorithms allows users to focus on the scientific problem at hand, rather than the implementation details of Bayesian modeling. The choice of Python as a development language, rather than a domain-specific language, means that PyMC users are able to work interactively to build models, introspect model objects, and debug or profile their work, using a dynamic, high-level programming language that is easy to learn. The modular, object-oriented design of PyMC means that adding new fitting algorithms or other features is straightforward. In addition, PyMC comes with several features not found in most other packages, most notably Hamiltonian-based samplers as well as automatic transforms of constrained random variables which is only offered by Stan. Unlike Stan, however, PyMC supports discrete variables as well as non-gradient based sampling algorithms like Metropolis-Hastings and Slice sampling.
Development of PyMC is an ongoing effort and several features are planned for future versions. Most notably, variational inference techniques are often more efficient than MCMC sampling, at the cost of generalizability. More recently, however, black-box variational inference algorithms have been developed, such as automatic differentiation variational inference (ADVI; Kucukelbir et al., 2017). This algorithm is slated for addition to PyMC. As an open-source scientific computing toolkit, we encourage researchers developing new fitting algorithms for Bayesian models to provide reference implementations in PyMC. Since samplers can be written in pure Python code, they can be implemented generally to make them work on arbitrary PyMC models, giving authors a larger audience to put their methods into use.
References#
Bastien, F., Lamblin, P., Pascanu, R., Bergstra, J., Goodfellow, I., Bergeron, A., Bouchard, N., Warde-Farley, D., and Bengio, Y. (2012) “Theano: new features and speed improvements”. NIPS 2012 deep learning workshop.
Bergstra, J., Breuleux, O., Bastien, F., Lamblin, P., Pascanu, R., Desjardins, G., Turian, J., Warde-Farley, D., and Bengio, Y. (2010) “Theano: A CPU and GPU Math Expression Compiler”. Proceedings of the Python for Scientific Computing Conference (SciPy) 2010. June 30 - July 3, Austin, TX
Duane, S., Kennedy, A. D., Pendleton, B. J., and Roweth, D. (1987) “Hybrid Monte Carlo”, Physics Letters, vol. 195, pp. 216-222.
Hoffman, M. D., & Gelman, A. (2014). The No-U-Turn Sampler: Adaptively Setting Path Lengths in Hamiltonian Monte Carlo. The Journal of Machine Learning Research, 30.
Jarrett, R.G. A note on the intervals between coal mining disasters. Biometrika, 66:191–193, 1979.
Lunn, D.J., Thomas, A., Best, N., and Spiegelhalter, D. (2000) WinBUGS – a Bayesian modelling framework: concepts, structure, and extensibility. Statistics and Computing, 10:325–337.
Neal, R.M. Slice sampling. Annals of Statistics. (2003). doi:10.2307/3448413. Patil, A., D. Huard and C.J. Fonnesbeck. (2010) PyMC: Bayesian Stochastic Modelling in Python. Journal of Statistical Software, 35(4), pp. 1-81
Stan Development Team. (2014). Stan: A C++ Library for Probability and Sampling, Version 2.5.0.