1.4. Lecture 2#
Follow-ups to Lecture 1 notebooks#
Notes on filling in the table in Checking the sum and product rules, and their consequences using Python:
fstring:
print(f'ratio = {ratio:.3f}')ornp.around(number,digits)How do you use numpy arrays?
experts: write function to work with either ints or floats or numpy arrays
Further takeaways from Exploring PDFs to discuss in class
Bayesian confidence intervals: how are they defined?
various “point estimates” (mean, mode, median); which is “best” to use?
characteristics of different pdfs (e.g., symmetry, heavy tails, …)
what does “sampling” mean?
Question
How do you know if a distribution with a known functional form has been correctly sampled?
Answer
When the samples are histogrammed (and normalized), they approach the distribution function more closely as the number of samples increases.
what are projected posteriors (relate these to marginalization over one of the variables)?
Bayesian updating via Bayes’ theorem#
Consider Bayes’ theorem for the case where we seek the pdf of parameters \(\thetavec\) contingent on some data.
\(\thetavec\) is a general vector of parameters (this is common notation in statistics)
The denominator is the data probability or “fully marginalized likelihood” or evidence or maybe some other name (these are all used in the literature). We’ll come back to it later. As will be clear later, it is a normalization factor.
The prior pdf is what information \(I\) we have (or believe) about \(\thetavec\) before we observe the data.
The posterior pdf is our new pdf for \(\thetavec\), given that we have observed the data.
The likelihood is the probability of getting the specified data given the parameters \(\thetavec\) under consideration on the left side. Note that the likelihood is to be considered as a function of \(\thetavec\) for fixed data.
\(\Longrightarrow\) Bayes’ theorem tells us how to update our expectations.
Note
Sometimes particular notation is used for the prior and likelihood. The prior is written with \(\pi\): \(p(\thetavec,I) \rightarrow \pi(\thetavec,I)\) and the likelihood with \(\mathcal{L}\): \(p(\text{data}|\thetavec,I) \rightarrow \mathcal{L}(\text{data}|\thetavec,I)\).
Coin tossing example to illustrate updating#
The notebook is Bayesian_updating_coinflip_interactive.ipynb.
Storyline: We are observing successive flips of a coin (or any binary process). There is a definite true probability of getting heads \((p_h)_{\text{true}}\), but we don’t know what the values is, other than it is between 0 and 1.
We characterize our information about \(p_h\) as a pdf.
Before any flips, we start with a preconceived notion of the probability; this is the prior pdf \(p(p_h|I)\), where \(I\) is any info we have.
With each flip of the coin, we gain additional information, so we update our expectation of \(p_h\) by finding the posterior
Note that the outcome is discrete (either heads or tails) but \(p_h\) is continuous \(0 \leq p_h \leq 1\).
Let’s first play a bit with the simulation and then come back and think of the details.
Note a few of the Python features:
there is a class for data called Data. Python classes are easy compared to C++!
a function is defined to make a type of plot that is used repeatedly
elaborate widget \(\Longrightarrow\) use it as a guide for making your own! (Optional!) Read from the bottom up in the widget definition to understand its structure.
Widget user interface features:
tabs to control parameters or look at documentation
set the true \(p_h\) by the slider
press “Next” to flip “jump” # of times
plot shows updating from three different initial prior pdfs
Class exercises
Tell your neighbor how to interpret each of the priors
Possible answers
uniform prior: any probability is equally likely. Is this uninformative? (More later!)
centered prior (informative): we have reason to believe the coin is more-or-less fair.
anti-prior: could be anything but most likely a two-headed or two-tailed coin.
What is the minimal common information about \(p_h\) (meaning it is true of any prior pdf)?
Answer
Things to try:
First one flip at a time. How do you understand the changes intuitively?
What happens with more and more tosses?
Try different values of the true \(p_h\).
Question
What happens when enough data is collected?
Answer
All posteriors, independent of prior, converge to a narrow pdf including \((p_h)_{\text{true}}\)
Follow-ups:
Which prior(s) get to the correct conclusion fastest for \(p_h = 0.4, 0.9, 0.5\)? Can you explain your observations?
Does it matter if you update after every toss or all at once?
Suppose we had a fair coin \(\Longrightarrow\) \(p_h = 0.5\)
Is the sum rule obeyed?
Proof of penultimate equality
More generally, \(x = p_h\) and \(y = 1 - p_h\) shows that the sum rule works in general.
The likelihood for a more general \(p_h\) is the binomial distribution:
But we want to know about \(p_h\), so we actually want the pdf the other way around: \(p(p_h|R,N)\). Bayes says
Note that the denominator doesn’t depend on \(p_h\) (it is just a normalization).
Claim: we can do the tossing sequentially or all at once and get the same result. When is this true?
Answer
When the tosses are independent.
What would happen if you tried to update using the same results over and over again?
So how are we doing the calculation of the updated posterior?
In this case we can do analytic calculations.
Case I: uniform (flat) prior#
Start with (1.7) but with the normalization \(\mathcal{N}\) included (so now an equality):
where we will suppress the “\(I\)” going forward. But
Recall Beta function
and \(\Gamma(x) = (x-1)!\) for integers.
and so evaluating the posterior for \(p_h\) for new values of \(R\) and \(N\) is direct: substitute (1.11) into (1.8). If we want the unnormalized result with a uniform prior (meaning we ignore the normalization constant \(\mathcal{N}\) that simply gives an overall scaling of the distribution), then we just use the likelihood (1.6) since \(p(p_h) = 1\) for this case.
Case II: conjugate prior#
Choosing a conjugate prior (if possible) means that the posterior will have the same form as the prior. Here if we pick a beta distribution as prior, it is conjugate with the coin-flipping likelihood. From the scipy.stats.beta documentation the beta distribution (function of \(x\) with parameters \(a\) and \(b\)):
where \(0 \leq x \leq 1\) and \(a>0\), \(b>0\). So \(p(x|a,b) = f(x,a,b)\) and our likelihood is a beta distribution \(p(R,N|p_h) = f(p_h,1+R,1+N-R)\) to agree with (1.6).
If the prior is \(p(p_h|I) = f(p_h,\alpha,\beta)\) with \(\alpha\) and \(\beta\) to reproduce our prior expectations (or knowledge), then by Bayes’ theorem the normalized posterior is
so we update the prior simply by changing the arguments of the beta distribution: \(\alpha \rightarrow \alpha + R\), \(\beta \rightarrow \beta + N-R\) because the (normalized) product of two beta distributions is another beta distribution. Really easy!
Check this against the code!
Look in the code where the posterior is calculated and see how the beta distribution is used. Verify that (1.13) is evaluated. Try changing the values of \(\alpha\) and \(\beta\) used in defining the prior to see the shapes.
The first updates explicitly
If the first toss is a head, then \(N=1\) and \(R=1\) so the new posterior for \(p_h\) is
so the prior just gets multiplied by a straight line from \(x=0\) to \(x=1\). (Note that we don’t have to worry about the slope or the combinatoric factor or any overall constant because we just care about the shape of the posterior.)
Now suppose the next toss is a tail, so \(N=2\), \(R=1\) and the posterior is (droping the constants)
so the prior gets multiplied by an inverted parabola peaked at \(p_h = 1/2\). If we have a large number of tosses and half of them are heads, then we get a steeper peaked likelihood function at \(p_h=1/2\) multiplying the prior. This will dominate any prior eventually as long as the prior is not equal to zero at \(p_h = 1/2\) and varies more slowly than the likelihood.
Try sketching this!
First look at the radioactive lighthouse problem#
This is from radioactive_lighthouse_exercise.ipynb.
A radioactive source emits gamma rays randomly in time but uniformly in angle. The source is at \((x_0, y_0)\).
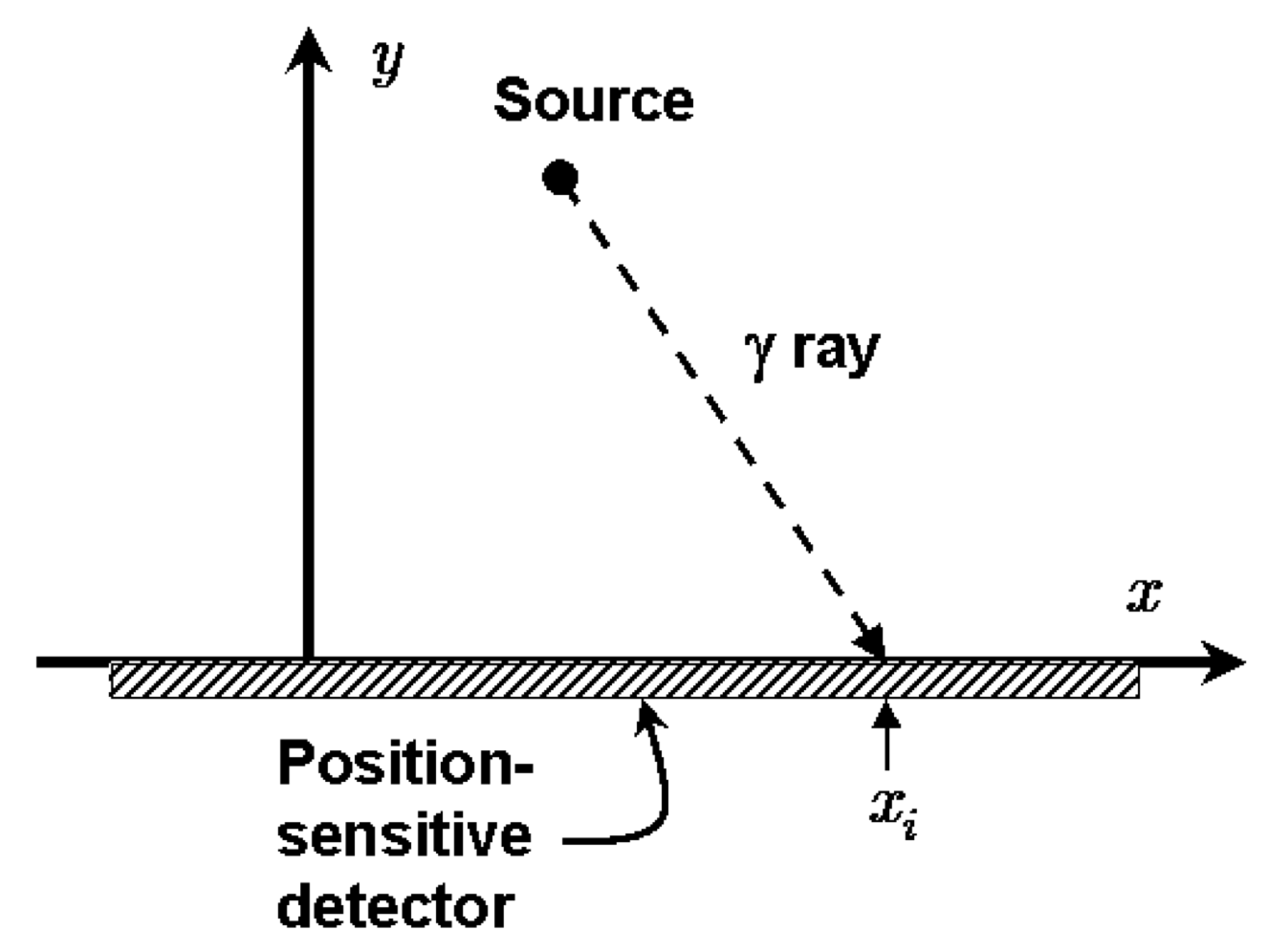
Gamma rays are detected on the \(x\)-axis and positions recorded, i.e., \(x_1, x_2, x_3, \cdots, x_N \Longrightarrow \{x_k\}\).
Goal: Given the recorded positions \(\{x_k\}\), estimate \((x_0, y_0)\). For the first pass we’ll take \(y_0 = 1\) as known, so we only need to estimate \(x_0\) (you will generalize later!).
Naively, how would you estimate \(x_0\) given \(x_1, \cdots, x_N\)? Probably by taking the average of the observed positions. Let’s compare this naive approach to a Bayesian approach.
Follow the notebook leading questions for the Bayesian estimate!