4.1. Lecture 9#
Why Bayes is Better I#
These examples were developed by Christian Forssén for the 2019 TALENT course at York, UK.
Notebooks we’ll use:
Summary: Advantages of the Bayesian approach#
1. Provides an elegantly simple and rational approach for answering, in an optimal way, any scientific question for a given state of information. This contrasts to the recipe or cookbook approach of conventional statistical analysis. The procedure is well-defined:
Clearly state your question and prior information.
Apply the sum and product rules. The starting point is always Bayes’ theorem.
For some problems, a Bayesian analysis may simply lead to a familiar statistic. Even in this situation it often provides a powerful new insight concerning the interpretation of the statistic.
2. Incorporates relevant prior (e.g., known signal model or known theory model expansion) information through Bayes’ theorem. This is one of the great strengths of Bayesian analysis.
For data with a small signal-to-noise ratio, a Bayesian analysis can frequently yield many orders of magnitude improvement in model parameter estimation, through the incorporation of relevant prior information about the signal model.
For effective field theories, information about the expansion can be explicitly included and tested.
3. Provides a way of eliminating nuisance parameters through marginalization. For some problems, the marginalization can be performed analytically, permitting certain calculations to become computationally tractable.
4. Provides a way for incorporating the effects of systematic errors arising from both the measurement operation and theoretical model predictions.
5. Calculates probability of hypothesis directly: \(p(H_i|D, I)\).
6. Provides a more powerful way of assessing competing theories at the forefront of science by automatically quantifying Occam’s razor.
Occam’s razor#
Occam’s razor is a principle attributed to the medieval philosopher William of Occam (or Ockham). The principle states that one should not make more assumptions than the minimum needed: “plurality should not be posited without necessity” or “Entities should not be multiplied without necessity”. It underlies all scientific modeling and theory building. It cautions us to choose from a set of otherwise equivalent models of a given phenomenon the simplest one. In any given model, Occam’s razor helps us to “shave off” those variables that are not really needed to explain the phenomenon.
It was previously thought to be only a qualitative principle. But there is a quantitative, Bayesian, version of Occam’s razor. We’ll have much more to say about this later when we discuss the Bayesian evidence in detail in a couple of weeks.
Nuisance parameters (I)#
Nuisance parameters are parameters we introduce to characterize a situation but which we don’t care about or know in detail. We could also call them “auxiliary variables”. The Bayesian way to deal with them is to marginalize, i.e., to integrate over them.
The procedure is illustrated in the notebook “A Bayesian Billiard game” and is quite generic, so it is worth looking at in detail. The discussion here is not as complete as the notebook. Be sure to run through the notebook as well.
Bayesian billiard schematic:
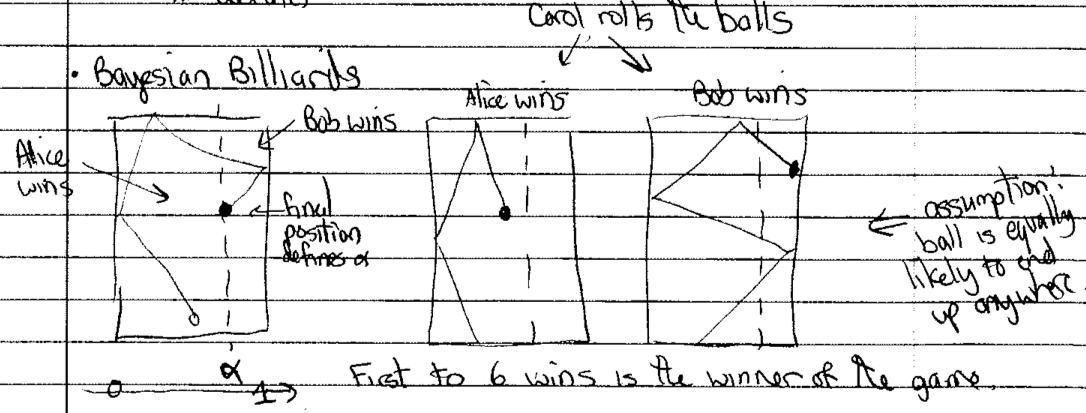
On a hidden billiard table (i.e., Alice and Bob can’t see it), Carol has randomly established \(\alpha\), which is the fraction of the table (\(0 \leq \alpha \leq 1\)) that defines whether Alice or Bob wins the roll. Alice gains a point if the ball ends up less than \(\alpha\), otherwise Bob gains a point. The first to six wins the game.
Capsule summary:
Carol knows \(\alpha\) but Alice and Bob don’t. \(\alpha \sim U(0,1)\).
Alice and Bob are betting on various outcomes.
After 8 rolls, the score is Alice 5 and Bob 3.
They are now going to bet on Bob pulling out an overall win.
Alice is most likely to win, as she only needs 1 winning roll out of 3, and there is already some indication she is favored.
What odds should Bob accept?
[Note: this is obviously not a physics problem but you can map it onto many possible experimental or theoretical physics situations. E.g., \(\alpha\) could be a normalization in an experiment (not between 0 and 1, but \(\alpha_{\text{min}}\) and \(\alpha_{\text{max}}\)) or a model parameter in a theory that we don’t know (we’ll see examples later!). In both cases we are not interested (usually) in the value of \(\alpha\); we want to eliminate it.]
Naive frequentist approach#
Here we start by thinking about the best estimate for \(\alpha\), call it \(\alphahat\). If \(B\) is the statement “Bob wins,” then what is \(p(B)\)?
Given the estimate \(\alphahat\), Bob winning a subsequent roll has probability \(1 - \alphahat\), and he must win 3 in a row \(\Lra\) \(p(B) = (1-\alphahat)^3\).
For future Bayesian reference: \(p(B|\alpha) = (1-\alpha)^3\) (i.e., if we know \(\alpha\) then the formula is the same).
Let’s find the maximum likelihood estimate for \(\alphahat\).
What is the likelihood of \(\alpha\) for the result Alice 5 and Bob 3?
This is a particular instance of the binomial distribution:
We have the combinatoric factor \({8 \choose 5}\) because we can get to Alice 5 and Bob 3 in any order (e.g., Alice wins 5 in a row and then Bob 3 in a row; or Alice wins 4, then Bob 3, then Alice 1; and so on).
Given \(\mathcal{L}(\alpha)\), find the maximum likelihood.
This estimate yields \(p(B) \approx 0.053\) or about 18 to 1 odds.
Bayesian approach#
You should try to fill in the details here!
What pdf is the goal here?
Find \(p(B|D,I)\) where \(D = \{n_A = 5, n_B = 3\}\).
What would \(I\) include here?
\(I\) includes all the details of the game, such as how \(\alpha\) enters and how the winner of each roll is determined.
Plan: introduce \(\alpha\) as a nuisance parameter. If we know \(\alpha\), the calculation is straightforward. If we only know it with some probability, then marginalize (i.e., do an appropriately weighted integral over \(\alpha\)).
Note that we can take several different equivalent paths to the same result:
What shall we do about \(p(\alpha|D,I)\)?
What was the naive frequentist distribution for \(p(\alpha|D,I)\)?
The naive frequentist used the MLE: \(p(\alpha|D,I) = \delta(\alpha-\alphahat)\).
The Bayesian approach is to use Bayes’ theorem to write \(p(\alpha|D)\) in terms of pdfs we know.
Write it out
What should we assume for the prior \(p(\alpha|I)\)?
The assumption is that there is no bias toward any value from 0 to 1, so we should assume a uniform, bounded pdf: \(p(\alpha|I) = 1\) for \(0 \leq \alpha \leq 1\) (with the implication that it is zero elsewhere).
In this situation we will need the denominator (unlike other examples of Bayes’ theorem we have considered so far) because we want a normalized probability.
How do we evaluate the denominator?
Note that we could write this directly or else first marginalize over \(\alpha\) and then apply the product rule. The interpretation is that the probability of getting a particular set of data can be found by averaging the probalibility of getting that data from all possible values of \(\alpha\), weighted by the probability of getting that \(\alpha\).
Now put it all together:
Find our goal!
where \(p(B|\alpha,D,I) = (1-\alpha)^3\) is just basic probability, \(p(D|\alpha)\) follows from binomial probabilities, and note that the combinatoric factor canceled out in the end.
Can you directly interpret the first integral? It is an average of the probability of \(B\) being true for a particular \(\alpha\), weighted by the (normalized) probability of that \(\alpha\).
What is the numerical result? Compare to the naive frequentist result.
or about 10 to 1 odds. Cf. 18 to 1 odds from our naive frequentist. [Note: you can evaluate the integrals by expanding or by using the beta function \(\beta(n,m) = \int_0^1 (1-t)^{n-1} t^{m-1}\, dt\).]
So the predicted results are very different!
Why were the estimates so different?
The frequentist evaluated the probability of Bob winning, \(p(B|\alpha,D,I)\) at the peak value of the weighting probability (maximum likelihood estimate), while the Bayesian integrated over that pdf. Because the pdf is very broad and asymmetric, these gave quite different answers.
How do we check who is correct?
In many cases we can do a Monte Carlo simulation (at least to validate test cases). See the notebook A Bayesian Billiard game for an implementation of this simulation. The result? Bayes wins!!!
Discussion points:
Introducing \(\alpha\) is straightforward in a Bayesian approach, and all assumptions are clear.
In general one introduces many such variables, which is how we can end up with posterior integrals we need to sample to do marginalization.
The problem with the “naive frequentist” approach is not that it is “frequentist” but that it is “naive”. (In this case an incorrect use of a MLE to predict the likelihood of the result \(B\).) But it is not easy to see how to proceed to take into account the need to sum over possibilities for \(\alpha\), while it is natural for Bayes. Bayes is better!
Python aside: How do we understand the Monte Carlo check?
The A Bayesian Billiard game notebook implements a Monte Carlo simulation of the Bayesian Billiard Game to find out empirically what the odds of Bob winning are. The Python code to do this may appear quite obscure to you. Let’s step through how we think of formulating the task and how it is carried out using Python methods. [Note for future upgrades: code it with a Pandas dataframe.]
# Setting the random seed here with an integer argument will generate the
# same sequence of pseudo-random numbers. We can use this to reproduce
# previous sequences. If call statement this statement without an argument,
# np.random.seed(), then we will get a new sequence every time we rerun.
# [Note: for NumPy > 1.17, the recommendation is not to use this function,
# although it will continue to work.
# See https://numpy.org/doc/stable/reference/random/generated/numpy.random.seed.html]
np.random.seed()
# Set how many times we will play a random game (an integer).
num_games = 100000
# Play num_games games with randomly-drawn alphas, between 0 and 1
# So alphas here is an array of 100000 values, which represent the true value
# of alpha in successive games.
alphas = np.random.random(num_games)
# Check out the shape and the first 10 values
alphas.shape
# alphas shape = (100000,)
alphas[0:10]
# array([0.78493534, 0.67468677, 0.75934891, 0.74440188, 0.42772768,
# 0.01775373, 0.86507125, 0.7817262 , 0.12253274, 0.59833343])
# Now generate an 11-by-num_games array of random numbers between 0 and 1.
# These represent the 11 rolls in each of the num_games games.
# We need at most 11 rolls for one player to reach 6 wins, but of course
# the game would be over if one player reaches 6 wins earlier.
# [Note: np.shape(rolls) will tell you the dimensions of the rolls array.]
rolls = np.random.random((11, len(alphas)))
# Check the shape and then show the 11 rolls for the first game
rolls.shape
# rolls shape = (11, 100000)
rolls[:,0]
# array([0.27554774, 0.87754685, 0.80245949, 0.58945847, 0.95515154,
# 0.15568279, 0.34747239, 0.94627455, 0.80451086, 0.75016319,
# 0.74861084])
# count the cumulative wins for Alice and Bob at each roll
Alice_count = np.cumsum(rolls < alphas, 0)
Bob_count = np.cumsum(rolls >= alphas, 0)
# To see how this works, first look at `rolls < alpha`
rolls < alphas
# array([[ True, True, True, ..., False, False, True],
# [False, False, True, ..., False, True, True],
# [False, True, True, ..., False, True, True],
# ...,
# [False, True, True, ..., False, True, True],
# [ True, True, False, ..., True, False, True],
# [ True, True, True, ..., False, False, True]])
# This is an 11 x 100000 array of Boolean values that compares
# the corresponding value in the rolls array to the values in
# the alpha array. Note that rolls[:,i] is compared to alphas[i]
# (i.e., for a given second index i in rolls, the comparison is
# the value for all 11 first indices to the same index i in alphas).
# Check the first game (a set of 11 rolls) explicitly:
rolls[:,0] < alphas[0]
# array([ True, False, False, True, False, True, True, False, False,
# True, True])
# This agrees with comparisons of the entries printed above (alpha[0] = 0.78493534).
# Now we add up how many rolls are won by Alice and Bob at each stage
# (so Alice_count and Bob_count have the same shape as rolls).
# We do this with np.cumsum, where the 0 argument means to do the
# cumulative sum along the 0 axis, meaning the first index (so 0 to 10).
# True = 1 and False = 0. The results for the first game are
Alice_count[:,0]
# array([1, 1, 1, 2, 2, 3, 4, 4, 4, 5, 6])
Bob_count[:,0]
# array([0, 1, 2, 2, 3, 3, 3, 4, 5, 5, 5])
# sanity check: total number of wins should equal number of rolls
total_wins = Alice_count + Bob_count
assert np.all(total_wins.T == np.arange(1, 12))
print("(Sanity check passed)")
# Just a check: the sum of the two arrays for each of the games
# should be the numbers from 1 to 12. To make this comparison
# with == we need to take the transpose of total_wins. np.all
# gives True only if all the results are true and then assert
# will throw an error if it returns False.
# Determine the number of games that meet our criterion of
# (A wins, B wins) = (5, 3), which means Bob's win count at eight rolls must
# equal exactly 3. Index 7 of Bob_count must therefore be 3.
# The expression: Bob_count[7,:] == 3 will be either True or False for each
# of the num_games entries. The sequence of True and False values will be
# stored in the good_games array. (Try looking at the good_games array.)
good_games = Bob_count[7,:] == 3
# If we apply .sum() to good_games, it will add 1 for True and 0 for False,
# so good_games.sum() is the total number of Trues.
print(f'Number of suitable games: {good_games.sum():d} ',
f'(out of {len(alphas):d} simulated ones)')
# Truncate our results to consider only the suitable games. We use the
# good_games array as a template to select out the True games and redefine
# Alice_count and Bob_count (we could also rename these arrays).
Alice_count = Alice_count[:, good_games]
Bob_count = Bob_count[:, good_games]
# Determine which of these games Bob won.
# To win, he must reach six wins after 11 rolls. So we look at the last
# value for all of the suitable games: Bob_count[10,:] and count how
# many equal 6 by using np.sum.
bob_won = np.sum(Bob_count[10,:] == 6)
print(f'Number of these games Bob won: {bob_won:d}')
# Compute the probability (just the ratio of games Bob won to the
# total number of games that satisfy Alice 5, Bob 3 after 8 games).
mc_prob = bob_won / good_games.sum()
print(f'Monte Carlo Probability of Bob winning: {mc_prob:.3f}')
print(f'MC Odds against Bob winning: {(1. - mc_prob) / mc_prob:.0f} to 1')